
はじめに
『AI論文ジャーナルクラブ』へようこそ。
この企画では最新の人工知能関連の論文を分かりやすく解説し、気になるポイントを考察していきます。
AI論文ジャーナルクラブでは、雑多なAI論文を効率的に読み進めていくために、Google NotebookLMなどのRAG技術を最大限活用しています。 Google NotebookLMなどのRAG(Retrieval-Augmented Generation)技術を活用することで、膨大な文献から必要な情報を迅速かつ的確に抽出し、非常に効率的に要点を把握し、内容を整理しながら高い精度と深さで読み進めることができます。まさに革命的です。
記事の構成は読み進めることで、より理解が深まる構成にしています。 この論文の詳細に興味あれば、最後のざっくりサマリー・図表の解説まで読み進めてください。
今回扱う論文記事では、テキストから画像を生成する際の人間による好みを学習し、それをモデルに反映させるための包括的なソリューションを提示しています。
論文タイトルと簡単要約
Title (English): ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
Title (日本語): ImageReward:テキストから画像生成における人間の好みを学習し評価する
Authors (English): Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
簡単要約 (日本語):
本論文では、テキストから画像を生成する際に人間の好みを学習し、モデルに反映させるための包括的な解決策であるImageRewardとReFLを提案しています。ImageRewardは、13万7千件の専門家による比較データに基づいて学習された、テキストから画像生成における人間の好みを評価する初の汎用的な報酬モデルです。このモデルは、既存のテキスト-画像スコアリング手法よりも人間の好みを良く捉えることが実験で示されています。また、ReFL(Reward Feedback Learning)は、ImageRewardのフィードバックに基づいて拡散モデルを直接最適化するアルゴリズムです。このアプローチにより、生成された画像のテキストとの整合性、品質、美的感覚が向上し、有害なコンテンツの生成を抑制することが期待されます。ImageRewardは、人間の選好を評価するための自動指標としても有望です。
初心者向けの分野背景と事前知識
- テキストから画像生成 (Text-to-Image): テキストの記述に基づいて画像を生成するAIモデル。自己回帰モデルと拡散モデルがあり、近年は拡散モデルが主流。
- 自己教師あり学習: 大量の画像とテキストのペアデータでモデルを事前学習。画像とテキストの関連性を学習するが、人間の好みとのずれが課題。
- 人間の好み: テキストと画像の整合性、画像の品質、美しさ、倫理的な問題など、複数の要素から構成される。
- RLHF: 人間のフィードバックに基づく強化学習。報酬モデルを訓練し、モデルを人間の好みに合わせる。NLP分野で活用。
- 画像評価指標: FIDやCLIPスコアなどがあるが、人間の好みを十分に捉えられない。
- 拡散モデルのノイズ除去: ノイズから徐々に画像を復元するプロセス。後期のステップで人間の好みが判断可能になる。
- ImageReward: 人間の好みを評価する報酬モデル。既存の評価指標より人間の好みに合致。
- ReFL: ImageRewardのフィードバックで拡散モデルを直接最適化するアルゴリズム。
- データセット: DiffusionDBなどの多様なデータセットを利用。専門家による詳細なアノテーションを実施。
- モデルの課題: テキストと画像の不整合、体の歪み、美観のずれ、有害コンテンツなど。ImageRewardとReFLでこれらの課題を解決。
主題、問題意識、手法、成果
主題: この論文の主題は、テキストから画像を生成する際に、人間の好みを学習し、それをモデルに反映させるための包括的な解決策を提示することです。特に、人間の主観的な好みを捉え、それをテキストから画像生成モデルの改善に活用することに焦点を当てています。
問題意識: 既存のテキストから画像生成モデルは、テキストとの整合性、画像の品質、美的感覚、および有害なコンテンツの生成において課題を抱えています。これらの課題は、モデルアーキテクチャや事前学習データの改善だけでは解決が難しいため、人間のフィードバックを取り入れる必要性があります。特に、モデルが人間の選好と乖離している点が問題視されています。
手法: この論文では、まず13万7千件の専門家による比較データを用いて、人間の選好を学習するImageRewardという報酬モデルを構築しました。さらに、このImageRewardからのフィードバックを用いて、拡散モデルを直接最適化するReFL(Reward Feedback Learning)というアルゴリズムを提案しました。これにより、生成プロセスにおけるノイズ除去の段階で、人間の好みに合致する画像を生成できるようにモデルを調整しています。
成果: ImageRewardは、既存のテキスト-画像スコアリング手法(CLIP、Aesthetic、BLIP)よりも人間の好みをより良く捉えることが実験的に示されました。また、ReFLは、データ拡張や損失の再重み付けなどの既存手法よりも優れており、テキストとの整合性、画像品質、美的感覚が向上し、有害コンテンツを避けた高品質な画像生成を実現しました。さらに、ImageRewardは、テキストから画像生成モデルを評価する自動指標としても有望であることが示されました。
生成AI・数学的な観点
生成AI的な観点からの特徴
- この論文は、テキストから画像を生成するモデルの出力が、人間の主観的な好みにどのように合致するかという、生成AIにおける重要な課題に取り組んでいます。
- 特に、ImageRewardという報酬モデルを導入することで、人間の美的感覚やテキストとの整合性といった複雑な要素を定量的に評価しようとしています。
- また、ReFLという新しい学習アルゴリズムを提案し、拡散モデルの生成プロセスを人間の好みに合わせて直接最適化しています。
- このアプローチは、従来のデータ拡張や損失の再重み付けといった間接的な手法ではなく、モデルの生成過程に直接フィードバックを反映させるという点で、生成AIの進歩に貢献しています。
- さらに、ImageRewardを自動評価指標として利用することで、生成モデルの比較や個々の画像の品質評価を効率的に行うことを目指しており、生成AIモデルの実用性を高める可能性を示唆しています。
数学的な観点からの特徴
- この論文では、人間の選好をランキングデータとして扱い、それを学習するための損失関数を定義しています。具体的には、比較される画像ペアの間で、好ましい画像に高いスコアを与えるようにモデルを訓練しています。
- ImageRewardの学習には、BLIPモデルをバックボーンとし、クロスアテンションとMLPを用いてテキストと画像の埋め込み表現を統合しています。
- ReFLでは、拡散モデルのノイズ除去プロセスにおける特定のステップで、ImageRewardのスコアを損失として利用し、勾配を逆伝播させることで、モデルのパラメータを更新しています。
- このアプローチは、拡散モデルの生成過程における潜在変数を直接操作し、人間が評価する画像の品質を向上させるための具体的な手法を提供しています。
- また、実験結果を定量的に評価するため、選好精度、再現率、フィルタリングスコアなどのメトリクスを使用しており、モデルの性能を客観的に比較しています。
ざっくりサマリー
この論文記事の全体像を把握するためのざっくりとしたサマリーです。
この論文では、テキストから画像を生成する際に、人間の主観的な好みを学習し、それをモデルに反映させるための包括的な解決策として、ImageRewardとReFLという二つの主要な技術を提案しています。
ImageReward は、テキストから画像を生成する際の人間の選好を評価するための報酬モデルです。このモデルは、13万7千件の専門家による比較データに基づいて学習されており、既存のテキスト-画像スコアリング手法(CLIP、Aesthetic、BLIP)よりも人間の好みをより正確に捉えることが示されています。ImageRewardは、テキストと画像の整合性、画像の品質(写実性や美的感覚)、および有害コンテンツの回避といった複数の側面を考慮して、画像を評価します。このモデルは、テキストと画像の埋め込み表現を統合し、人間の選好を数値化する能力を持っています。
ReFL(Reward Feedback Learning) は、ImageRewardからのフィードバックを活用して、拡散モデルを直接最適化するアルゴリズムです。従来の拡散モデルの改善手法は、データ拡張や損失の再重み付けなどの間接的なアプローチに頼っていましたが、ReFLは、モデルの生成過程におけるノイズ除去の特定のステップで、ImageRewardのスコアを損失として利用し、勾配を逆伝播させることで、モデルのパラメータを直接更新します。これにより、生成される画像のテキストとの整合性、品質、美的感覚が向上し、有害なコンテンツの生成が抑制されることが期待されます。ReFLは、拡散モデルが持つ生成過程における中間表現を活用し、人間の選好をモデルに直接反映させるという点で、革新的な手法です。
さらに、この論文では、以下の点も強調されています。
- ImageRewardは、テキストから画像を生成するモデルを評価するための自動指標としても有望であり、モデルの性能比較や個々の画像の品質評価を効率的に行うことができる。これは、人間の評価を模倣したモデルを構築し、それを用いてモデルの評価を自動化するという、より実用的な視点からの貢献です。
- 人間の選好を学習するための体系的なアノテーションパイプラインを設計し、専門家による質の高い比較データを収集しました。このパイプラインは、プロンプトの選択、アノテーションの管理、人間のアノテーション設計、アノテーションの分析という複数の段階で構成されており、高品質なアノテーションデータを収集するための基準や手順を確立しています。
- 実験結果から、ReFLは既存の拡散モデルの改善手法よりも優れており、より高品質で人間が好む画像を生成できることが示されました。これにより、生成AIモデルの出力を人間の期待に近づけるための実用的な手法を提供しています。
この論文の貢献は、テキストから画像生成における人間の主観的な好みをモデルに統合するための新しいアプローチを提示した点にあります。ImageRewardとReFLを組み合わせることで、より高品質で人間が好む画像を生成できるだけでなく、生成モデルの評価や改善のための新しい枠組みを提供しました。また、アノテーションパイプラインの設計やデータセットの公開も、今後の研究にとって重要な貢献です。
図表の解説

- Figure 1: この図は、テキストから画像生成における課題と、ImageRewardおよびReFLによる改善例を示しています。上段は、異なるテキスト-画像スコアモデルによって選択された画像の例で、テキストとの整合性、体の描写、美的感覚、有害性の問題を示しています。下段は、ReFLによる改善例で、これらの問題が軽減されていることがわかります。
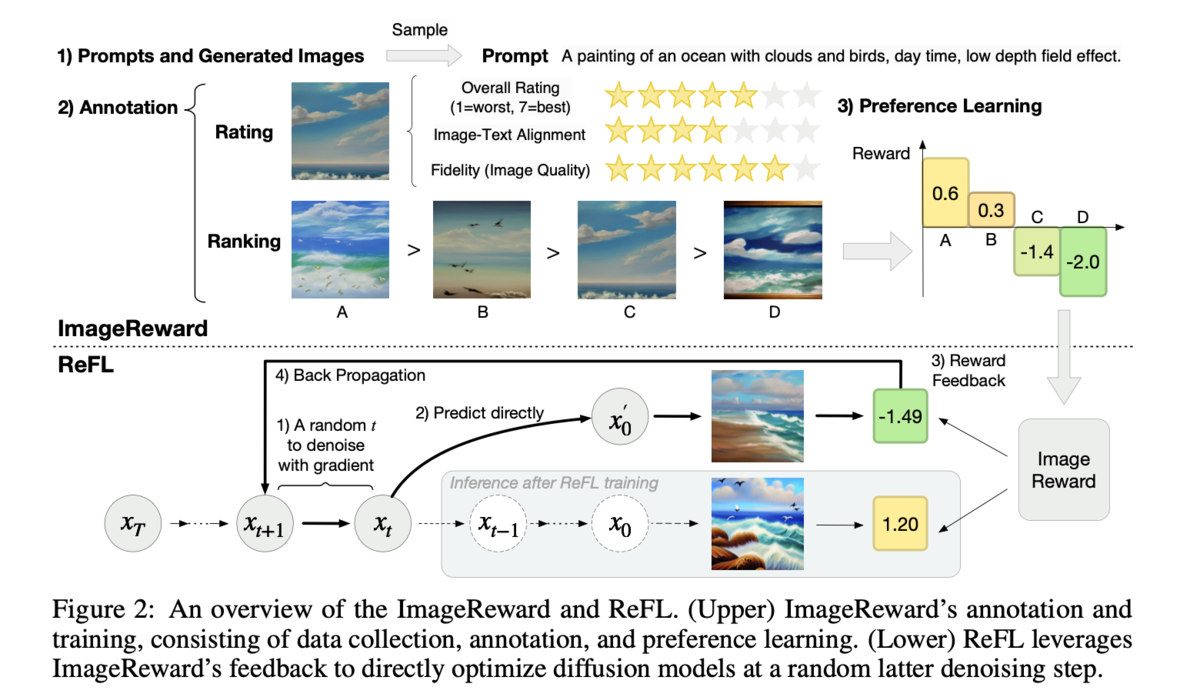
- Figure 2: この図は、ImageRewardとReFLの全体像を示しています。上部はImageRewardのアノテーションと学習プロセスを示し、プロンプトと生成された画像の収集、アノテーション、選好学習の段階を示しています。下部はReFLがImageRewardのフィードバックを利用して拡散モデルを最適化する様子を示しており、ノイズ除去の後半段階で直接最適化を行うことを示しています。
- Figure 3: この図は、異なる生成モデルにおけるImageRewardとCLIPのスコア分布を比較しています。ImageRewardのスコア分布は、CLIPよりもモデル間およびサンプル間の品質の識別能力が高いことを示しています。また、ImageRewardのスコアの中央値は人間のランキングとよく一致していることが示されています。
- Figure 4: この図は、拡散モデルのノイズ除去ステップにおけるImageRewardのスコアの変化を示しています。ノイズ除去の初期段階ではスコアが低いものの、30ステップ以降でスコアが明確に識別可能になることを示しています。この観察が、ReFLがノイズ除去の後期ステップで直接最適化を行う根拠となっています。
- Figure 5: この図は、ImageRewardと他のモデルを比較した場合の勝率を示しています。ImageRewardは、BLIP、Aesthetic、CLIPなどのモデルと比較して、より好ましい画像を選択できる割合が高いことがわかります。特に、多数の生成画像から上位3つを選択する場合にImageRewardの優位性が顕著です。
- Figure 6: この図は、異なるLDM最適化手法間での勝率を示しており、ReFLが他の手法よりも勝率が高いことを示しています。

- Figure 7: この図は、ReFLと他の微調整手法による生成画像の質的な比較を示しています。ReFLで微調整されたモデルは、テキストとの整合性が高く、人間が好む画像を生成する傾向があることがわかります。例えば、「尖った耳」のような詳細な記述も忠実に再現していることがわかります。
Appendix
- Figure 8: この図は、アノテーションシステムのスクリーンショットを示しています。上部 (a) はテキスト-画像ペアの評価段階で、テキストとの整合性、忠実性、全体の満足度を7段階で評価する様子を示しています。下部 (b) は画像ランキング段階で、複数の生成画像を順位付けする様子を示しています。
- Figure 9: この図は、アノテーションデータにおけるプロンプトのカテゴリ分布を示しています。アノテーションデータが、多様なトピックをカバーしていることを示しています。
- Figure 10: この図は、プロンプトのカテゴリごとの平均スコアを示しています。抽象的なプロンプトはスコアが低く、風景や具体的なオブジェクトを描写するプロンプトのスコアが高い傾向があることがわかります。
- Figure 11: この図は、プロンプトのカテゴリごとの問題発生頻度を示しています。特に、体の問題が頻繁に発生していることがわかります。
- Figure 12: この図は、プロンプトにおける機能語の割合と平均スコアの関係を示しています。機能語の割合が増加するにつれて、画像テキストの整合性、忠実度、および総合的な満足度が向上する傾向があることがわかります。
- Figure 13: この図は、機能語の割合で分類したプロンプトにおける問題の発生頻度を示しています。機能語の割合によって、画像の繰り返し生成、身体の問題、ぼやけといった問題の発生頻度が変化することがわかります。
- Figure 14: この図は、画像選択時のトレードオフの例を示しています。テキストとの整合性、忠実性、無害性の優先順位を示すことで、アノテーターの判断を助けます。
- Figure 15: この図は、各モデルが選択した最上位と最下位の画像の平均スコアを示しています。ImageRewardは、上位画像の平均スコアを最大化し、下位画像の平均スコアを最小化することで、優れた画像の選別能力を示しています。
- Figure 16: この図は、異なるモデルがランク付けした画像と、人間が選択した最高の画像、最悪の画像の分布を示しています。ImageRewardは、最も高い確率で最高の画像をランク付けし、最悪の画像を最低ランクにランク付けしています.
- Figure 17: この図は、異なるモデル間の補間による精度を示しています。ImageRewardと他のモデルを組み合わせても、単独で利用した場合より大きな精度向上は見られないことがわかります。
- Figure 18: この図は、PickScoreとImageRewardの学習セットにおけるプロンプトの分布をt-SNEで可視化したものです。ImageRewardの学習セットの方が、PickScoreの学習セットと比較して、より均等に分布していることがわかります。
- Figure 19: この図は、ノイズ除去のステップにおけるImageRewardスコアを示しています。左図は、ノイズ除去のステップごとのスピアマンの順位相関係数を示し、右図は、元々の報酬とトレーニング済みの報酬に対するImageRewardスコアの相関を示しています。
- Figure 20: この図は、異なるファインチューニング手法間の勝率を示しています。ReFLが他の手法と比較して最も高い勝率を示していることを示しています。
- Figure 21、22: これらの図は、ReFLと他のファインチューニング手法による生成画像の例をさらに示しています。ReFLが生成した画像は、テキストとの整合性が高く、望ましい結果を生み出していることがわかります。
- Figure 23, 24, 25, 26: これらの図は、ImageRewardと他の一般的な画像スコアリング手法(Random, Aesthetic, CLIP, BLIP)との質的比較を示しています。ImageRewardが他の手法よりも、テキストとの整合性が高く、忠実度の高い画像を選択していることが示されています。
- Table 1: この表は、異なるテキストから画像生成モデルの人間によるランキングと自動評価指標(ImageReward, CLIP, FID)を示しています。ImageRewardが人間の評価と最もよく一致しており、他の指標(CLIP, FID)は人間の評価と一致しないことがわかります。
- Table 2: この表は、(a)アノテーター、研究者、モデル間のアグリーメントと、(b)ImageRewardのバックボーンとデータセットサイズに関するアブレーションスタディの結果を示しています。アノテーターの合意は高く、バックボーンにBLIPを用いた場合、データセットの規模を大きくすると精度が向上することがわかります。
- Table 3: この表は、ImageRewardと他の手法の人間選好予測の精度を示しています。ImageRewardは他のベースラインモデルよりも高い精度を示しており、特にRecallとFilterのスコアが高いことがわかります。
- Table 4: この表は、異なるLDM最適化手法の人間評価を示しています。ReFLは、総勝率とSD v1.4ベースラインに対する勝率で最高の結果を達成しています。
- Table 5: この表は、ImageRewardと他の報酬モデルの人間選好予測の結果を示しています。ImageRewardは、他のモデルよりも高い精度、Recall、Filterスコアを示しています。
- Table 6: この表は、異なる報酬モデルの比較を示しています。ImageRewardは、他のモデルと比較して、人間評価での勝率が高く、報酬スコアも高いことがわかります。