
はじめに
『AI論文ジャーナルクラブ』へようこそ。
この企画では最新の人工知能関連の論文を分かりやすく解説し、気になるポイントを考察していきます。
この企画では最新の人工知能関連の論文を分かりやすく解説し、気になるポイントを考察していきます。 AI論文ジャーナルクラブでは、雑多なAI論文を効率的に読み進めていきます。
Google NotebookLMなどのRAG技術を最大限活用しています。Google NotebookLMなどのRAG(Retrieval-Augmented Generation)技術を活用することで、膨大な文献から必要な情報を迅速かつ的確に抽出し、非常に効率的に要点を把握し、内容を整理しながら高い精度と深さで読み進めることができます。まさに革命的です。 記事の構成は読み進めることで、より理解が深まる構成にしています。 この論文の詳細に興味あれば、最後のざっくりサマリー・図表の解説まで読み進めてください。 最終的には、原著論文を読むときに事前知識やヘルプとなればと思います。
今回扱う論文記事では、2023年のGPT-4 レポートです。この報告書では、GPT-4の性能を様々な試験やベンチマークで評価するとともに、安全性や倫理的な側面、潜在的な偏見などについても詳細に分析がなされています。
初心者向けの分野背景と事前知識
この論文記事をより深く理解するために必要な、初心者向けの分野背景と事前知識を以下に解説します。
- 大規模言語モデル(LLM): 大量のテキストデータを学習し、人間のような自然な文章を生成するAIモデル。GPT-4はその最先端モデルの一つです。
- Transformer: LLMの基盤となるニューラルネットワークアーキテクチャ。Self-Attention機構により、文中の単語間の関係性を捉えるのが得意です。
- マルチモーダル:テキストだけでなく、画像などの複数の種類のデータを扱えるモデル。GPT-4は画像とテキストを組み合わせて処理できます。
- RLHF (強化学習による人間のフィードバック): モデルの挙動を人間の好みに合わせるための訓練手法。安全性を高めるために重要です。
- ベンチマーク: モデルの性能を客観的に評価するためのテストデータセット。様々な試験(学術、専門)でGPT-4の能力を測っています。
- Contamination(汚染/混入): 評価データが訓練データに含まれてしまうこと。性能評価の信頼性を損なうため、注意が必要です。
- プロンプト: LLMに対する指示文。プロンプトの設計によって、モデルの出力が大きく変わります。
- 安全性:有害なコンテンツの生成を抑制し、倫理的な問題を防ぐための対策。GPT-4の開発における重要な課題の一つです。
- 倫理的配慮: 偏見や差別を助長しないように、モデルの挙動を調整すること。社会的な影響を考慮する必要があります。
- System Card: AIモデルの機能、制限事項、安全性に関する情報を提供するドキュメント。透明性を高めるために重要です。
論文タイトルと簡単要約
- タイトル(英語):GPT-4 Technical Report
- タイトル(日本語):GPT-4 技術報告書
- 著者名(英語):Sandhini Agarwal, Greg Brockman, Miles Brundage, Adrien Ecoffet, Tyna Eloundou, David Farhi, Johannes Heidecke, Shengli Hu, Joost Huizinga, Roger Jiang, Gretchen Krueger, Jan Leike, Daniel Levy, Stephanie Lin, Ryan Lowe, Tong Mu, Hyeonwoo Noh, Jakub Pa-chocki, Jack Rae, Kendra Rimbach, Shibani Santurkar, Szymon Sidor, Benjamin Sokolowsky, Jie Tang, Chelsea Voss, Kai Xiao, Rowan Zellers, Chong Zhang, Marvin Zhang et al.
- 雑誌名:(雑誌論文ではないため、雑誌名はありません)
- 出版年:2023年
- 簡単な要約(日本語): GPT-4は、画像とテキストを入力として受け入れ、テキストを出力できる大規模なマルチモーダルモデルです。この報告書では、GPT-4の性能を様々な試験で評価し、その結果、多くの試験で人間の上位の成績を収めることが示されています。また、安全性を向上させるための対策や、倫理的な側面についても詳しく分析されています。特に、有害なコンテンツの生成を抑制するためのRBRM(ルールに基づく報酬モデル)などの技術が紹介されています。さらに、汚染(評価データが訓練データに含まれること)の影響を調査し、GPT-4の性能評価の信頼性を検証しています。この報告書は、GPT-4の能力と限界、そして今後の開発における課題を示す重要な資料です。
主題、問題意識、手法、成果
- 主題:GPT-4という大規模マルチモーダルモデルの能力、限界、および安全性に関する特性を包括的に評価・分析すること。
- 問題意識:GPT-4のような大規模モデルが、広範な応用可能性を持つ一方で、安全性や倫理面で潜在的なリスクを抱えている点。特に、有害コンテンツの生成や偏見の助長といった問題に対処する必要性があります。
- 手法:
- 多様な試験ベンチマークを用いたGPT-4の性能評価。
- RLHF(強化学習による人間のフィードバック)によるファインチューニングの効果測定。
- RBRM(ルールに基づく報酬モデル)を用いた安全性向上のための技術の導入と評価。
- Contamination(評価データの訓練データへの混入)の影響の検証。
- 成果:
- GPT-4が多くの試験で人間の上位の成績を収めることを実証。
- RLHFがモデルの安全性を向上させることを確認。
- Contaminationが性能評価に与える影響は小さいことを示す。
- RBRMが有害コンテンツの生成を抑制するのに有効であることを確認。
生成AI・数学的な観点
レポートがでた、2023年当時時点での生成AIとGPT-4を、生成AI的な観点、数学的な観点からの特徴を説明します。
生成AI的な観点: GPT-4は、大規模言語モデルとして、テキストと画像をマルチモーダルに入力し、Transformerアーキテクチャに基づいてテキストを生成します。RLHF(人間のフィードバックによる強化学習)により、ユーザーの意図に沿った出力を生成する能力が向上し、安全性も高められています。以前のモデルに比べて、より複雑で微妙なシナリオでの自然言語理解と生成が可能です。多様なベンチマークで高い性能を示し、APIを通じてアクセス可能であり、さまざまな応用が期待されていました。
数学的な観点: GPT-4は、Transformerモデルをベースにしており、自己注意メカニズムを通じて文脈を理解します。損失関数のスケーリング則に基づいてモデルの性能を予測し、計算資源の効率的な利用を図っています。RLHFでは、人間のフィードバックを報酬関数として強化学習を行い、モデルの挙動を最適化します。RBRM(ルールに基づく報酬モデル)を用いて、安全性に関する制約を組み込むことも可能です。ただし、事後学習によってキャリブレーションが低下する場合があります。





ざっくりサマリー
この報告書では、GPT-4の性能、安全性、および潜在的なリスクに焦点を当てています。
以下に、ドキュメントの要点をまとめます。
- GPT-4の性能:
- GPT-4は、内部コードベースから導出されたデータセットで最終損失を測定した結果、小規模モデルの性能を上回ることが示されています。
- HumanEvalデータセットのサブセットにおける平均ログパス率の測定でも、GPT-4は小規模モデルよりも高い性能を示しました。
- 様々な学術および専門試験において、GPT-4はGPT-3.5を上回る性能を発揮しました。例えば、GRE(大学院進学共通試験)の定量、言語セクションで高いスコアを記録しています。
- GPT-4の安全性:
- GPT-4の能力と限界は、バイアス、偽情報、過度の依存、プライバシー、サイバーセキュリティ、拡散など、重要かつ新たな安全性の課題を提起します。
- OpenAIは、ドメイン専門家との敵対的テストやモデル支援による安全パイプラインなど、潜在的な危害を軽減するための介入を実施しました。
- RLHF(強化学習による人間のフィードバック)による微調整は、ベースモデルの能力を大幅には変化させないことが示唆されています。
- GPT-4は、禁止されているコンテンツに対する不適切な挙動の割合が、以前のモデルよりも大幅に低くなっています。
- GPT-4の能力:
- GPT-4は、画像に関する質問に答えることができ、視覚入力を理解する能力を**備えています。
- 図やグラフから情報を読み取り、計算を実行する能力を**示しています。
- 複数の言語での質問に答えることができ、多言語対応能力を**持っています。
- コーディング問題において、高い合格率を達成しており、コーディング能力が向上しています。
- GPT-4のリスクと制限:
- GPT-4は、説得力のある偽情報を生成する可能性があり、悪意のある目的に使用される可能性があります。
- GPT-4は、サイバーセキュリティの分野で役立つ一方で、脆弱性の悪用や高度なサイバー攻撃の実行には限界があります。
- GPT-4は、特定のタスクにおいて、不正確または不適切な情報を提供する可能性があり、注意して使用する必要があります。
- 安全対策:
- OpenAIは、使用ポリシーを策定し、モデルの悪用を防ぐための監視体制を構築しています。
- レッドチームによるテストを実施し、モデルの弱点を特定し、改善を**行っています。
この報告書は、GPT-4の潜在的なリスクを認識しつつ、その能力を最大限に活用するための安全対策の重要性を強調しています。
図表の解説
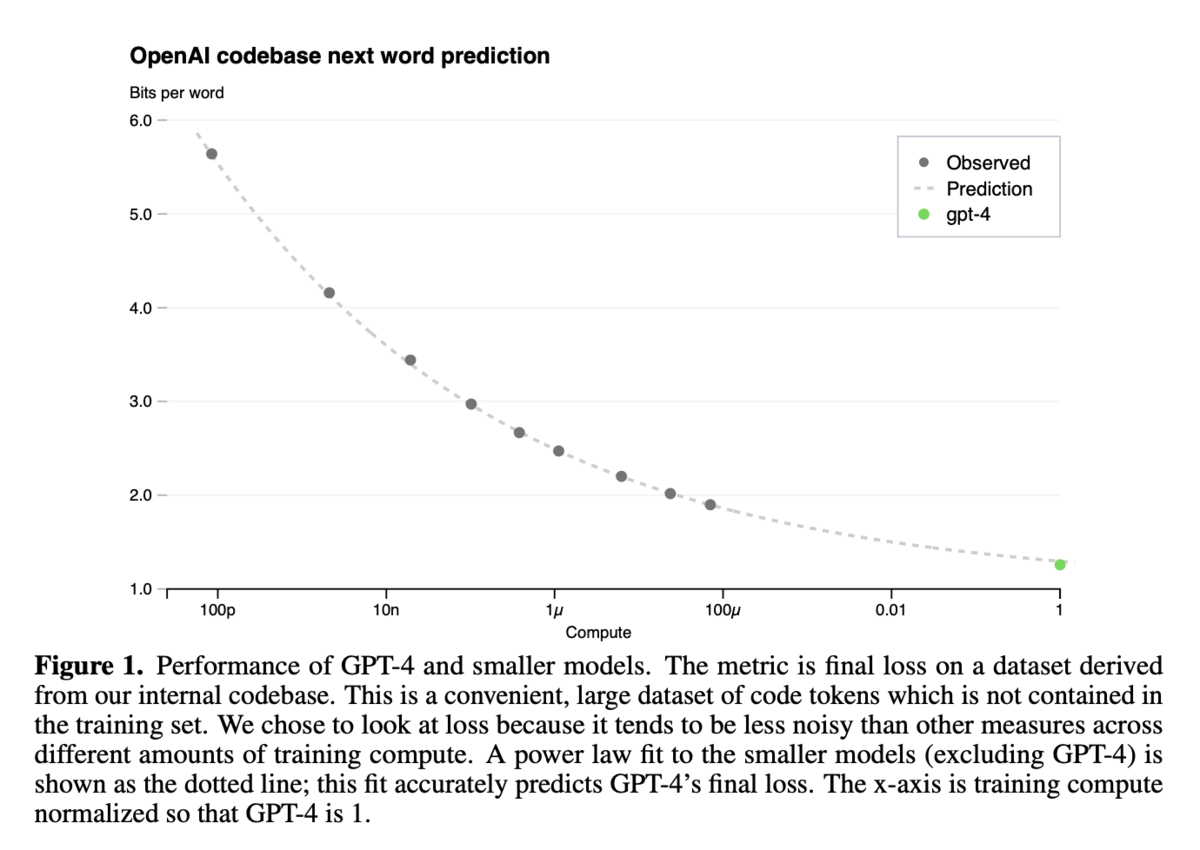
図1:GPT-4と小規模モデルの性能比較(OpenAI内部コードベース)
- GPT-4と比較して計算量が少ないモデルを用いて、OpenAIの内部コードベースにおける損失を予測しています。GPT-4の最終損失は、小規模モデルから予測されたスケーリング則にほぼ一致しています。
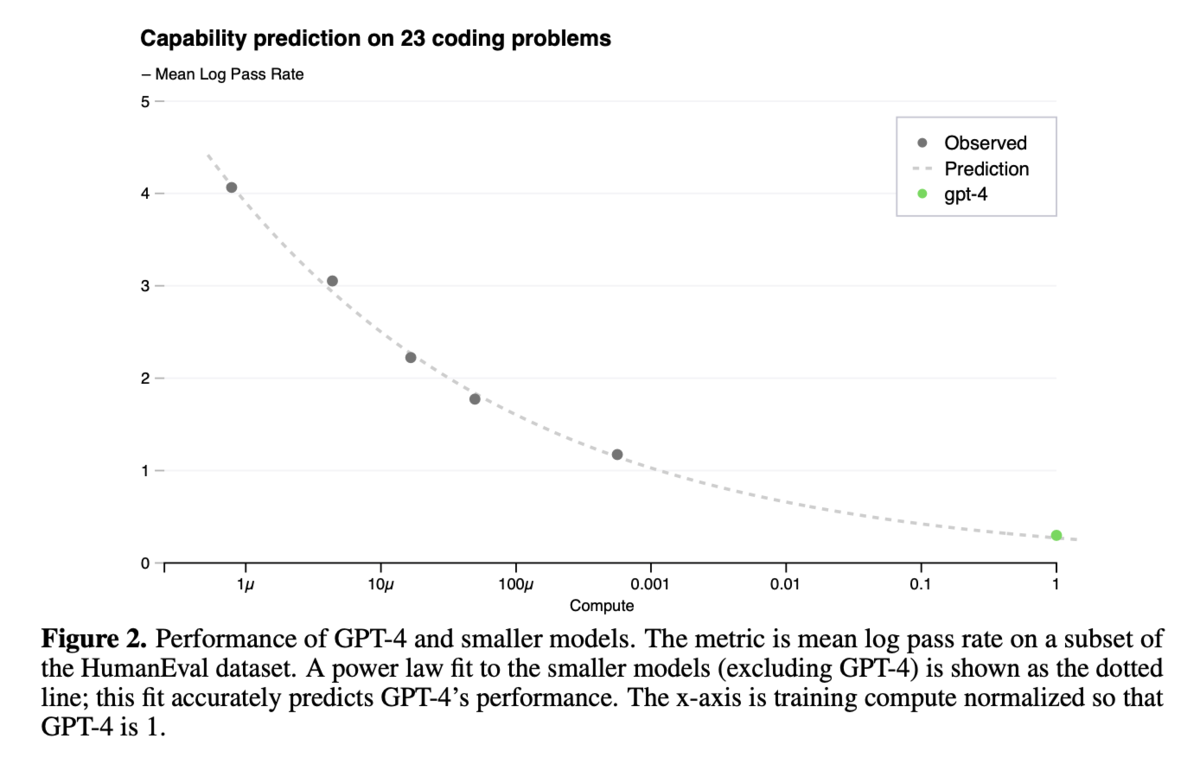
図2:GPT-4と小規模モデルの性能比較(HumanEvalデータセット)
- HumanEvalデータセットのサブセットにおける平均ログパス率を指標として、GPT-4と小規模モデルの性能を比較しています。GPT-4の性能は、小規模モデルから予測されたスケーリング則にほぼ一致しています。
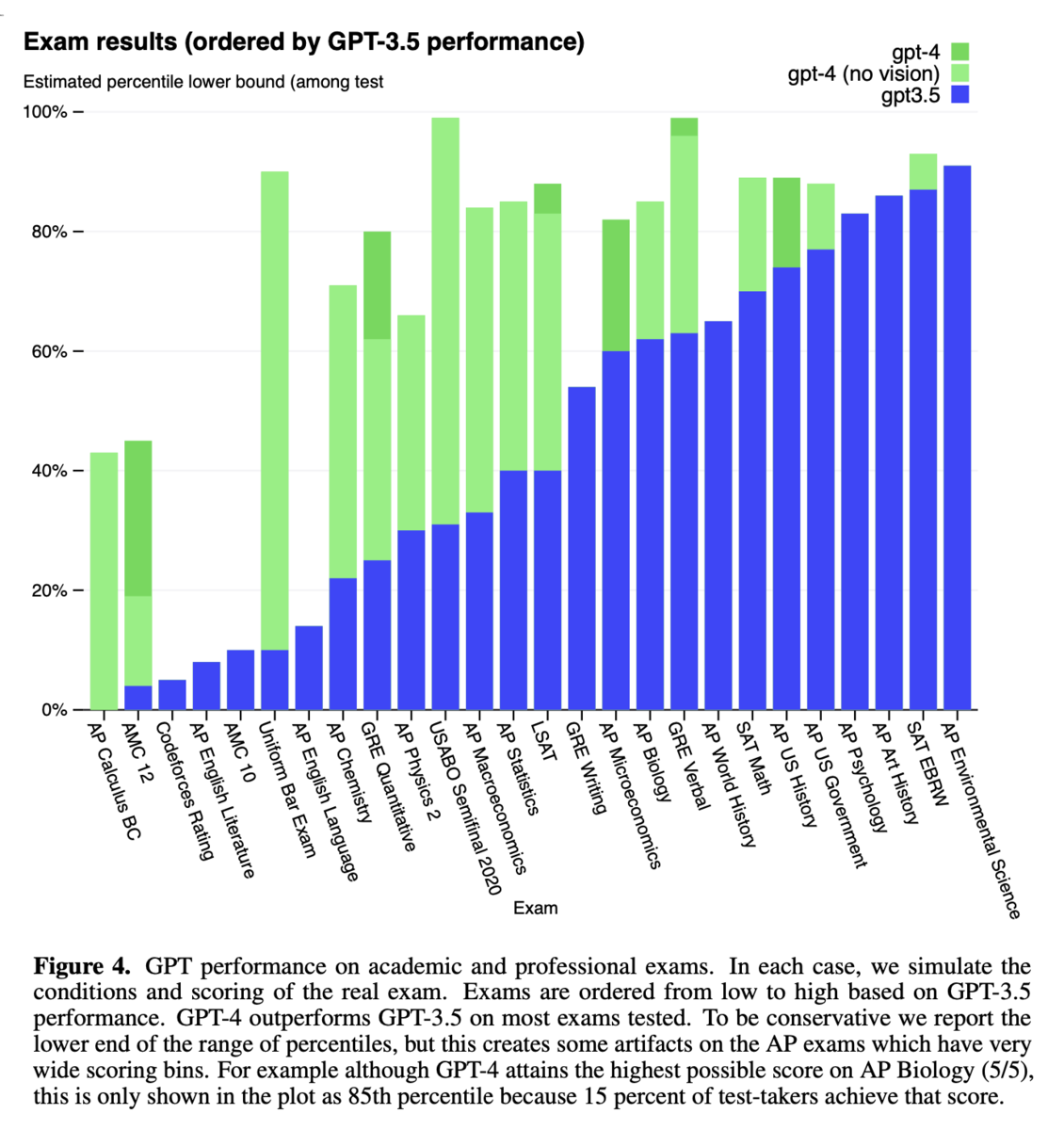
図4:学術・専門試験におけるGPTの性能
- GPT-4、GPT-4(視覚なし)、GPT-3.5の学術試験および専門試験における性能を比較しています。GPT-3.5の性能を基準に試験を並べており、GPT-4がGPT-3.5を上回ることが示されています。
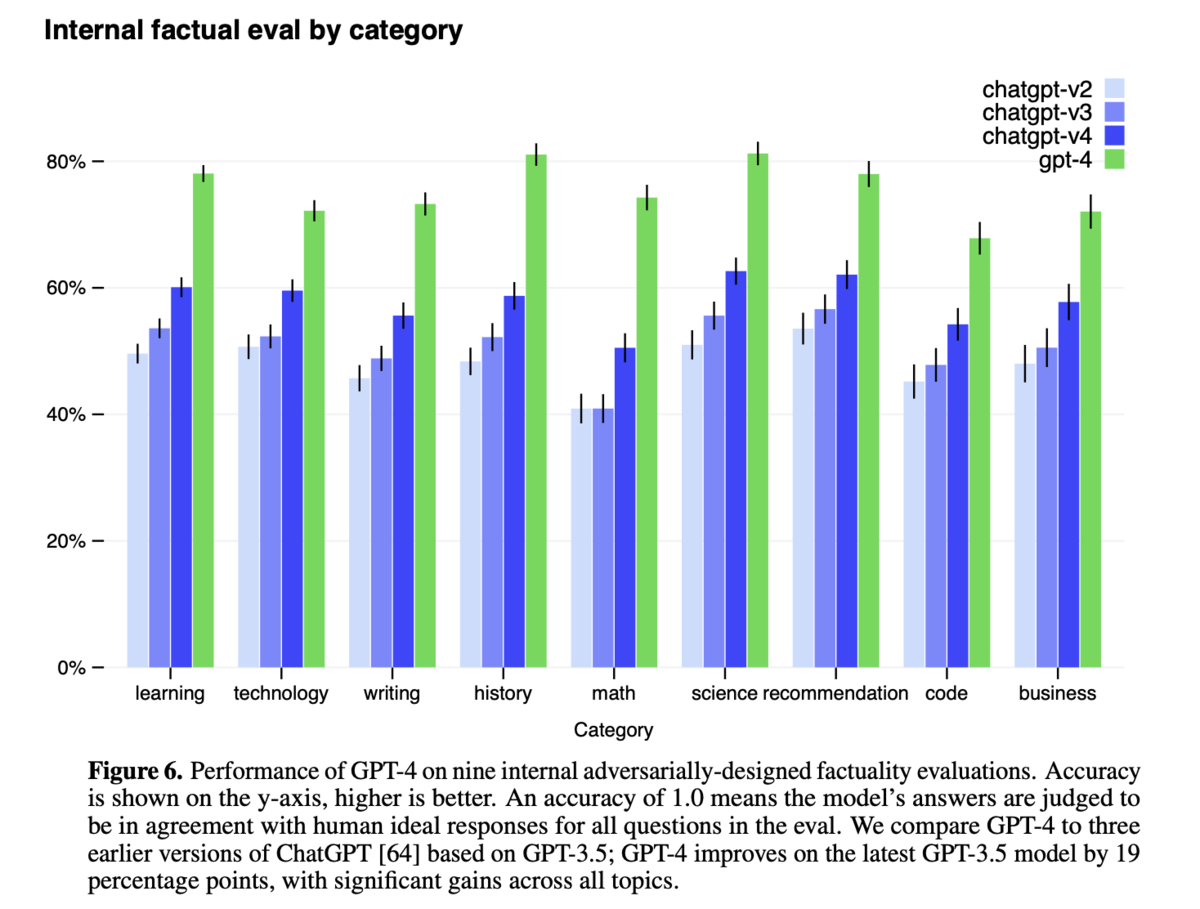
図6:敵対的な質問に対する内部事実性評価
- GPT-4と以前のChatGPTのバージョンを比較し、GPT-4が最新のGPT-3.5モデルよりも19パーセントポイント向上していることが示されています。
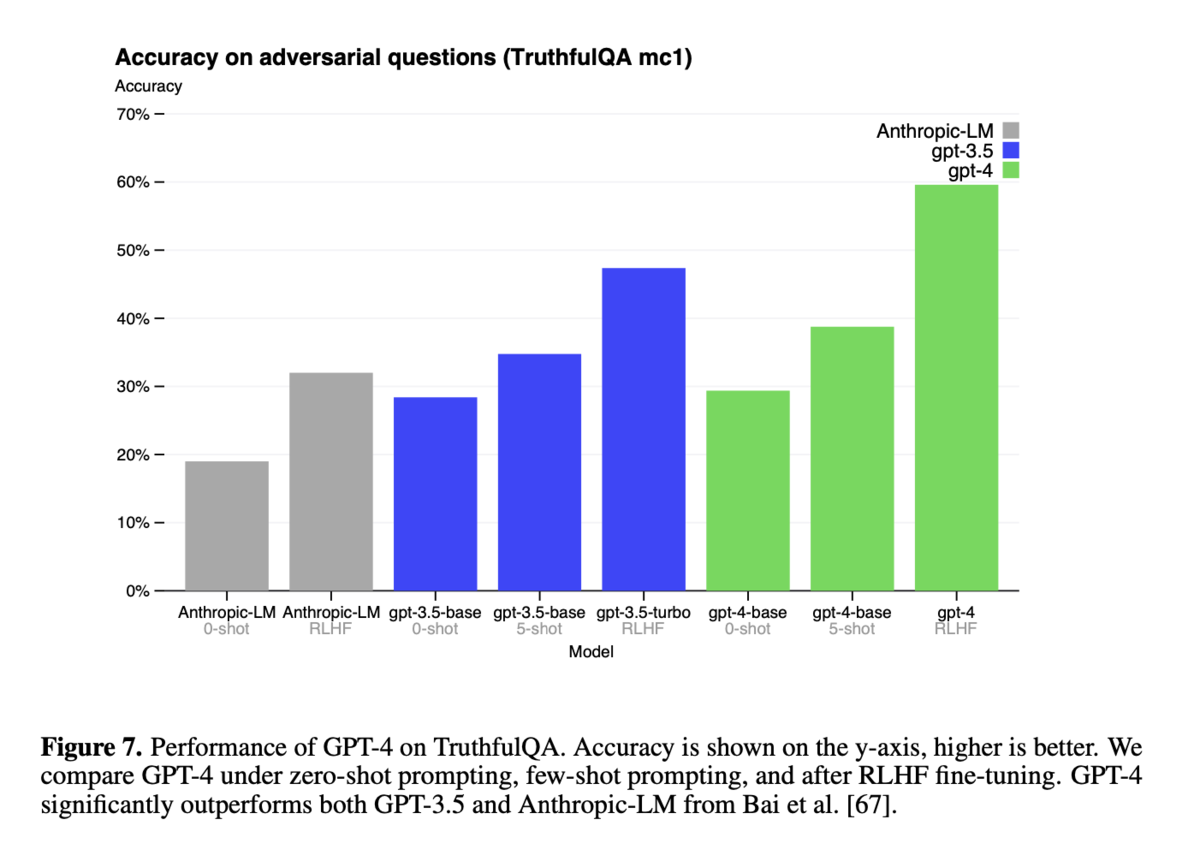
図7:TruthfulQAにおけるGPT-4の性能
- TruthfulQAにおけるGPT-4の性能を示しています。GPT-4は、GPT-3.5と比較して大幅に優れていることが示されています。
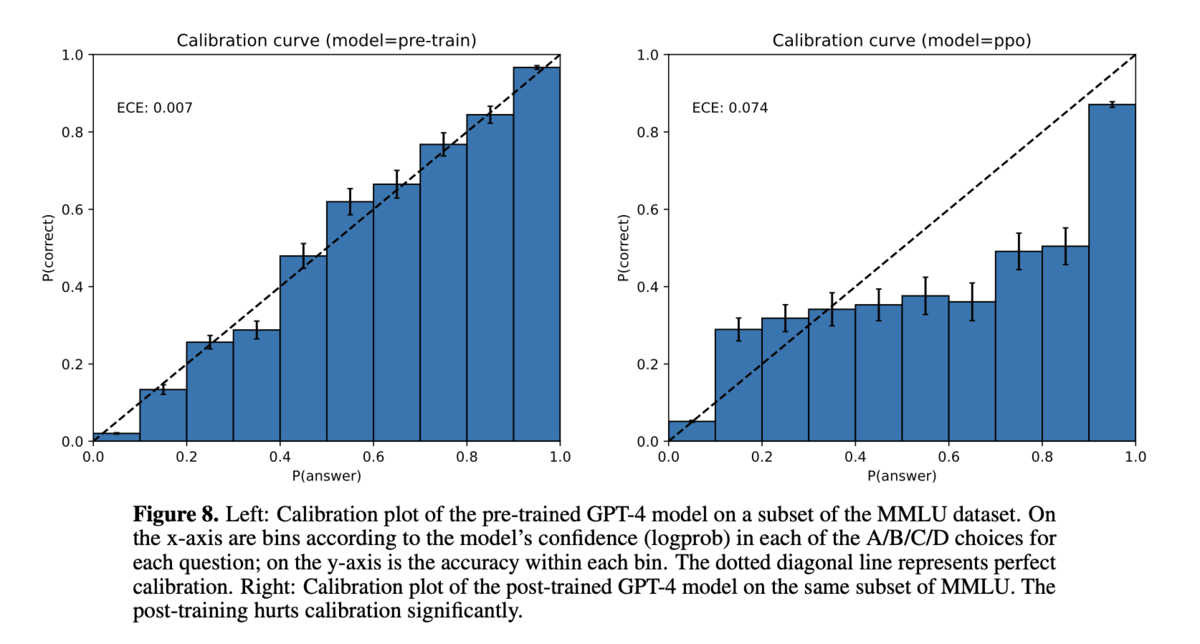
図8:MMLUデータセットにおけるGPT-4のキャリブレーションプロット
- 事前学習済みのGPT-4モデルと事後学習済みのGPT-4モデルのキャリブレーションを比較しています。事後学習はキャリブレーションを大幅に損なうことが示されています。
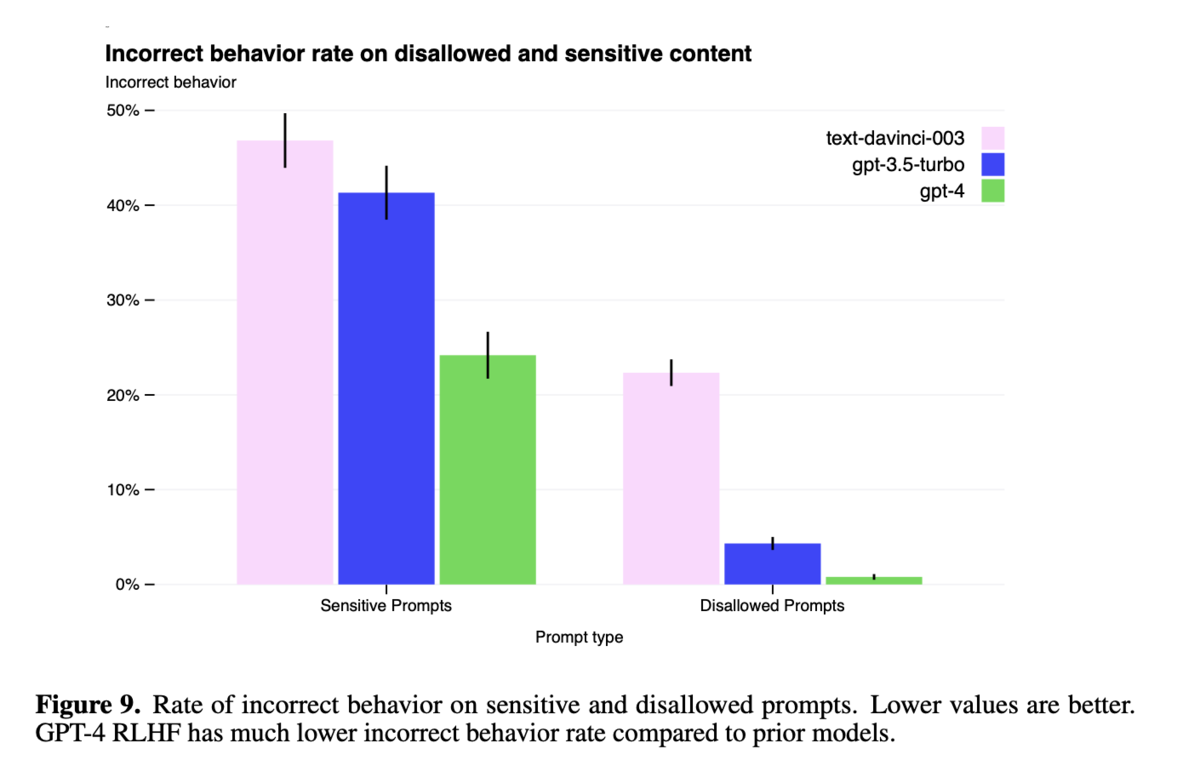
図9:禁止されたプロンプトと機密性の高いプロンプトに対する不適切な挙動の割合
- GPT-4 RLHFは、以前のモデルと比較して、機密性が高く禁止されているプロンプトに対する不適切な挙動の割合が大幅に低いことが示されています。