
はじめに
『AI論文ジャーナルクラブ』へようこそ。
この企画では最新の人工知能関連の論文を分かりやすく解説し、気になるポイントを考察していきます。
この企画では最新の人工知能関連の論文を分かりやすく解説し、気になるポイントを考察していきます。 AI論文ジャーナルクラブでは、雑多なAI論文を効率的に読み進めていきます。
Google NotebookLMなどのRAG技術を最大限活用しています。Google NotebookLMなどのRAG(Retrieval-Augmented Generation)技術を活用することで、膨大な文献から必要な情報を迅速かつ的確に抽出し、非常に効率的に要点を把握し、内容を整理しながら高い精度と深さで読み進めることができます。まさに革命的です。 記事の構成は読み進めることで、より理解が深まる構成にしています。 この論文の詳細に興味あれば、最後のざっくりサマリー・図表の解説まで読み進めてください。 最終的には、原著論文を読むときに事前知識やヘルプとなればと思います。
今回扱う論文記事のテーマは、AIによる科学的発見の自動化です。
初心者向けの分野背景と事前知識
この記事を深く理解するために必要な初心者向けの分野背景と事前知識を、冗長にならない程度で解説します。
- 自然言語処理(NLP):言語をAIに処理させる技術。文章の生成や翻訳、質問応答などに使われ、論文の自動レビューにも応用。
- 大規模言語モデル(LLM):大量のテキストデータで学習したAI。GPT-4oなどがあり、自然な文章生成や複雑なタスクの実行が可能。
- 論文レビュープロセス:研究の質を保証する仕組み。専門家が論文の妥当性や新規性を評価し、改善点を指摘。
- メタレビュー:複数のレビューを集約し、総合的な評価を行うこと。AIがメタレビューを生成することで、効率化が期待される。
- 自動論文生成:AIが論文を自動で作成する技術。アイデア出しから実験、論文執筆までを自動化し、研究の加速を目指す。
- 強化学習:Q学習などの手法を用いて、AIが試行錯誤しながら最適な行動を学習する。論文の質を向上させるために応用。
- 拡散モデル:ノイズからデータを生成する生成モデルの一種。低次元データへの応用が研究されており、論文生成にも利用。
- Transformer:注意機構を用いた深層学習モデル。言語モデリングや翻訳に優れており、論文の自動生成に不可欠。
- Grokking:訓練データに対する過学習後に汎化性能が劇的に向上する現象。AIの学習プロセスを理解する上で重要。
- Semantic Scholar API:論文情報を検索するためのAPI。AIが論文の新規性を判断する際に文献調査に利用。
論文タイトルと簡単要約
- タイトル(英語):The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
- タイトル(日本語):AI科学者:完全自動化されたオープンエンドな科学的発見に向けて
- 著者名(英語):Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, David Ha
- 出版年:2024年
要約(日本語): この論文では、AIが科学的な発見を自動化する試み「AI Scientist」を紹介しています。大規模言語モデル(LLM)を活用し、アイデアの生成、実験の設計、論文の執筆、レビューといった科学研究のプロセスを自動化することを目指しています。特に、Grokking現象の分析や、拡散モデルの改善、Transformerの学習に関する実験に焦点を当てています。AIによる論文レビューやメタレビューの可能性も探求し、科学研究の加速と効率化への貢献を目指しています。
主題、問題意識、手法、成果
主題、問題意識、手法、成果をそれぞれ述べます。
- 主題:AIによる科学的発見の完全自動化。AI Scientistというシステムを構築し、アイデア出しから論文執筆までを自動化することを目指す。
- 問題意識:従来の科学研究は時間と労力がかかる。Grokking現象など、未解明な学習現象の理解も課題。低次元データにおける拡散モデルの性能向上も目指す。
- 手法:大規模言語モデル(LLM)であるGPT-4oを活用し、アイデア生成、実験設計、論文執筆を自動化。強化学習(Q学習)やデータ拡張などの技術も応用。自動レビューシステムも開発。
- 成果:AI Scientistによる論文生成のプロトタイプを開発。拡散モデルやTransformerの学習に関する実験を実施し、Grokking現象の分析など、新たな知見を得る。自動レビューシステムの性能を評価し、改善の方向性を示す.
生成AI・数学的な観点
生成AI的な観点:
- 大規模言語モデル(LLM) が、アイデア出しから論文執筆まで研究プロセスを自動化。GPT-4o などのLLMを活用し、自然言語生成能力を最大限に引き出す。実験計画、コード生成、結果の分析、論文の構成といった複雑なタスクを、プロンプトとツールを組み合わせることで実現。自動レビューシステムもLLMで構築し、論文の品質評価を行う。
数学的な観点:
- 拡散モデルは、ノイズ除去のプロセスを確率微分方程式としてモデル化。KLダイバージェンスを評価指標として、生成されたサンプルの品質を定量化。Transformerの学習では、AdamWなどの最適化アルゴリズムを使用し、学習率の調整にQ学習を応用。Grokking現象の分析では、訓練と検証の精度をモニタリングし、汎化性能の向上を評価。Minimal Description Length (MDL) の概念を用いて、モデルの複雑さと汎化性能の関係を解析。

ざっくりサマリー
この論文記事の内容全体をざっくりと理解するためのサマリーを作成します。
この論文は、最先端の大規模言語モデル(LLM)を活用して、科学研究の全工程―アイデア生成、実験設計・実施、結果の解析、論文作成、そして査読―を自動化するフレームワーク「The AI Scientist」を提案しています。システムは、与えられたシンプルなコードテンプレートを出発点とし、LLMを駆使して新たな研究アイデアを生み出し、実験計画を立て、コードの修正や実行を行い、その結果をもとに論文を自動生成します。さらに、自動査読システムを用いることで、生成された論文の評価が人間の査読者に近い精度で実施され、低コスト(1論文あたり約15ドル)で多くの研究成果を蓄積できる仕組みが実現されています。
論文内では、拡散モデル、トランスフォーマーベースの言語モデル、そして学習ダイナミクス(grokking現象)の3つの分野でこの手法の有用性が示され、各分野ごとに詳細な実験結果やケーススタディ(例:Adaptive Dual-Scale Denoising)が紹介されています。また、実験結果は、従来の手法や人間の評価と比較しながら、システムの性能や課題が明確に示されており、例えばアイデアの重複、実装エラー、生成論文のフォーマット問題など、現状の限界も議論されています。
さらに、完全自動化による研究プロセスの透明性や倫理的なリスクにも触れ、将来的な改良と安全性の確保が求められる点が指摘されています。全体として、本研究はAIによる科学研究の自動化の可能性を初めて包括的に示すものであり、今後の研究の効率化や民主化に向けた新たなアプローチとして大きな意義を持っています。
- 主題:「AI Scientist」というAIシステムを開発し、科学研究の全プロセス(アイデア出しから論文執筆まで)を完全自動化することを目指す。
- 問題意識:
- 従来の科学研究は時間と労力がかかり、コストも高い。
- Grokking現象のような未解明な学習現象の理解を深めたい。
- 低次元データにおける拡散モデルの性能向上を目指したい。
- 手法:
- 大規模言語モデル(LLM)(GPT-4oなど)を活用し、アイデア生成、実験設計、論文執筆、レビューを自動化。
- 拡散モデル、GAN、Transformerなどの機械学習モデルを実験し、Q学習やデータ拡張などの技術を応用。
- 自動レビューシステムを開発し、生成された論文の品質を評価。
- KLダイバージェンスやMDLなどの数学的指標を用いて、モデルの性能や学習プロセスを分析。
- 成果:
- AI Scientistのプロトタイプを開発し、論文生成の可能性を示す。
- 拡散モデルやTransformerの学習に関する実験を実施し、Grokking現象の分析など、新たな知見を得る。
- 自動レビューシステムの性能を評価し、改善の方向性を示す。
- 約15ドルという低コストで論文を生成できる可能性を示唆。
- 生成AI的な観点:
- LLMが研究プロセスを自動化し、自然言語生成能力を最大限に活用。
- 複雑なタスクをプロンプトとツールの組み合わせで実現。
- 自動レビューシステムもLLMで構築し、論文の品質評価を行う。
- 数学的な観点:
- 拡散モデルを確率微分方程式としてモデル化し、KLダイバージェンスで品質を定量化。
- Transformerの学習に最適化アルゴリズムやQ学習を応用。
- MDLでモデルの複雑さと汎化性能の関係を解析。
要するに、AIによる科学研究の自動化を目指すための試みであり、LLMや機械学習、数学的分析を組み合わせることで、新たな科学的発見の加速に貢献する可能性を示唆しています。
図表の解説
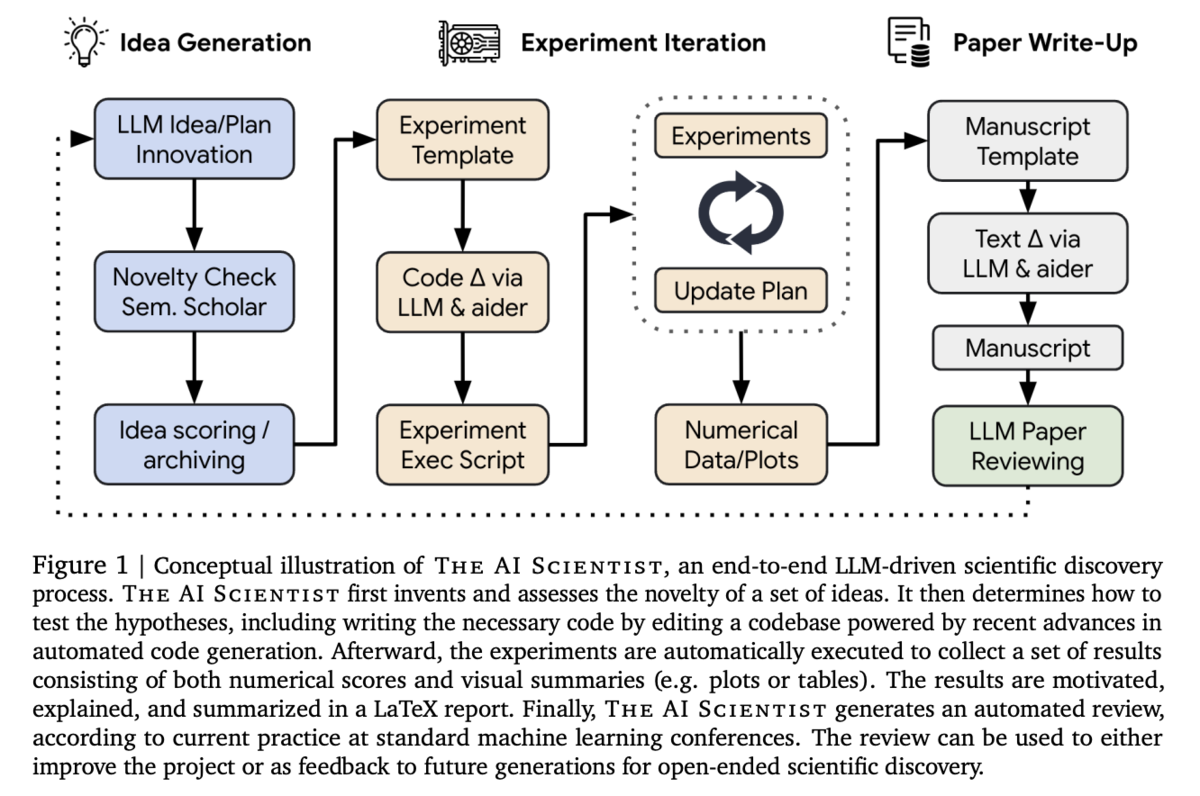
【Figure 1】
この図は、The AI Scientist の全体プロセスを概念的に示しています。まず、AIが既存のコードテンプレートをもとに多様な研究アイデアを生成し、その中から新規性や実現可能性を評価。その後、実験計画を立案し、コード修正と実験実行を経て得られた数値データや可視化結果を用いて論文を自動生成し、最終的に自動査読を実施する一連の流れが、ループ状に連続する形で表現されています。
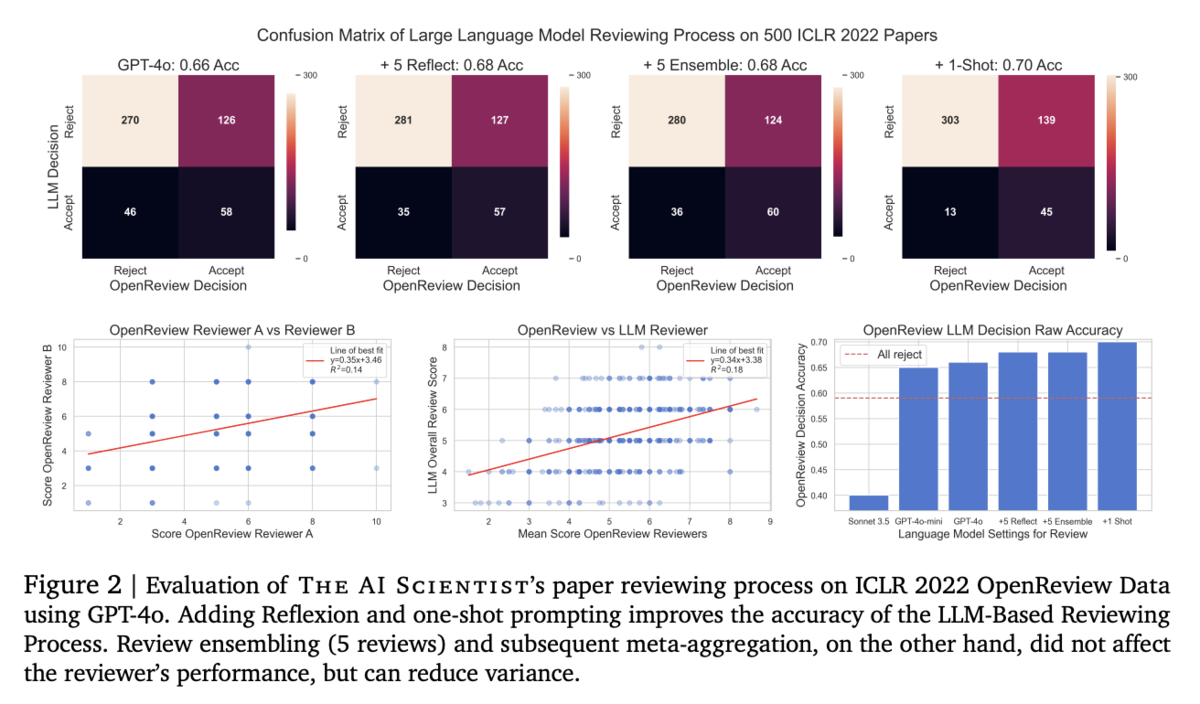
【Figure 2】
この図は、ICLR 2022 の論文データを用いて評価した自動査読システムの性能分布をバイオリンプロットで示しています。各プロンプト設定(反省プロンプトや 1-shot 提示)の効果や、レビュー結果のばらつき、ヒトレビューとの相関関係など、システムの査読精度と信頼性の改善状況を視覚的に把握できる内容となっています。

【Figure 3】
この図は、「Adaptive Dual-Scale Denoising」というタイトルの自動生成論文のプレビューを示しています。論文は、コード変更の詳細説明、実験結果の数値やグラフ、そして生成された論文全体の構成が含まれており、AIが独自に研究のアイデアを実験・検証し、論文執筆まで完結させたプロセスの成果が視覚的に確認できる点が強調されています。
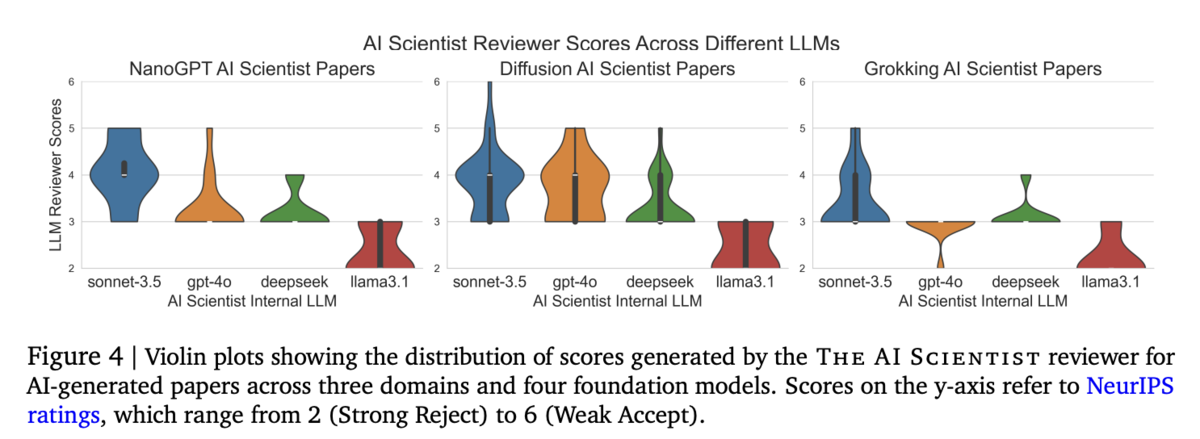
【Figure 4】
この図は、3つの研究分野における AI生成論文の評価スコアの分布を示すバイオリンプロットです。各分野や使用された基盤モデルごとに、査読スコア(2:強い却下から6:弱い受理まで)のばらつきや集中度が視覚的に表現され、システムの生成結果がどの程度一貫しているか、また各モデル間の性能差が比較できる内容となっています。
【Table 1】
この表は、ICLR 2022 論文500件に対して実施した自動査読システムの評価結果をまとめています。ヒト査読との比較や、ランダムな決定、常に却下する手法といった基準と共に、Sonnet 3.5、GPT-4o-mini、GPT-4o(0-shot/1-shot)など各モデルの査読精度(バランス精度、正答率、F1スコア、AUC、誤検出率など)が数値と信頼区間付きで示され、システムの性能の強みと課題が明確に把握できる構成です。
【Table 2】
この表は、3つの異なるテンプレートを用いて生成された 10 件の論文タイトルと、それに対する自動査読システムの評価スコアを一覧にまとめています。各論文は、2D Diffusion、NanoGPT、Grokking の各分野に分類され、タイトルから内容の概要が垣間見え、平均して NeurIPS の受理基準に近いスコア(約6前後)を示すことで、全体としての生成論文の質や分布が一目で理解できるようになっています。
【Table 3】
この表は、拡散モデルに関する論文生成の評価結果を示しており、各モデル(Sonnet 3.5、GPT-4o、DeepSeek Coder、Llama-3.1)の生成したアイデア総数、うち新規性の高いアイデア、実験成功数、完成した論文数、平均スコア、最高スコア、そして総コストがまとめられています。各指標を通じて、モデルごとの生成能力やコスト効率、性能のばらつきが比較され、低次元拡散モデルにおける実験の実用性と可能性が具体的に評価されています。
【Table 4】
この表は、言語モデルに関する論文生成の評価結果をまとめたものです。各モデル(Sonnet 3.5、GPT-4o、DeepSeek Coder、Llama-3.1)について、生成されたアイデア数、新規性が認められたアイデア数、実験通過数、完成論文数、平均及び最大評価スコア、そして総コストが記載されています。これにより、トランスフォーマーを用いた次トークン予測タスクでの生成性能や、実験の質、コスト効率が明示され、各モデルの相対的な強みと弱みが把握できる内容となっています。
【Table 5】
この表は、Grokking 現象に焦点を当てた論文生成の評価結果を示しています。各モデル(Sonnet 3.5、GPT-4o、DeepSeek Coder、Llama-3.1)について、総アイデア数、うち新規性のあるアイデア数、実験通過数、完成論文数、平均評価スコア、最高スコア、総コストが詳細にまとめられています。これにより、学習ダイナミクスにおける「grokking」現象の再現性や、生成論文の質、費用対効果が比較的明確に評価され、各モデルのパフォーマンスの違いが浮き彫りにされています
.