
サイコロゲーム - 序章
サイコロを振って、1から6のそれぞれの目が出る確率は、等しいと仮定する。
いわゆる、一様分布に従うと考える。
Rでは、一様分布に従う、1〜6までの整数値の乱数は、以下で表される。
as.integer( runif(1, min = 1, max = 7) )
この乱数で、サイコロの振る舞いはシミュレーションできるので、ちょっとしたアニメーションを作ってみた。
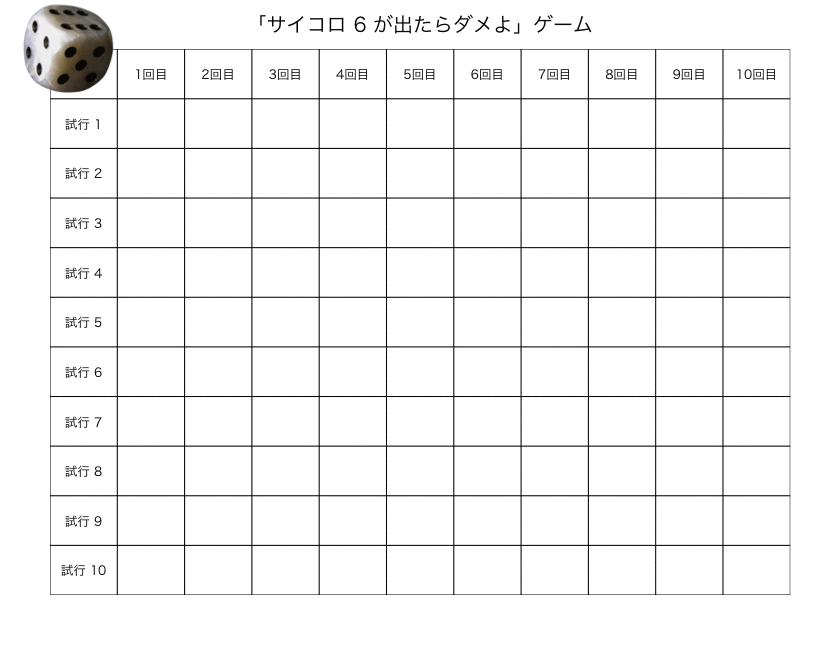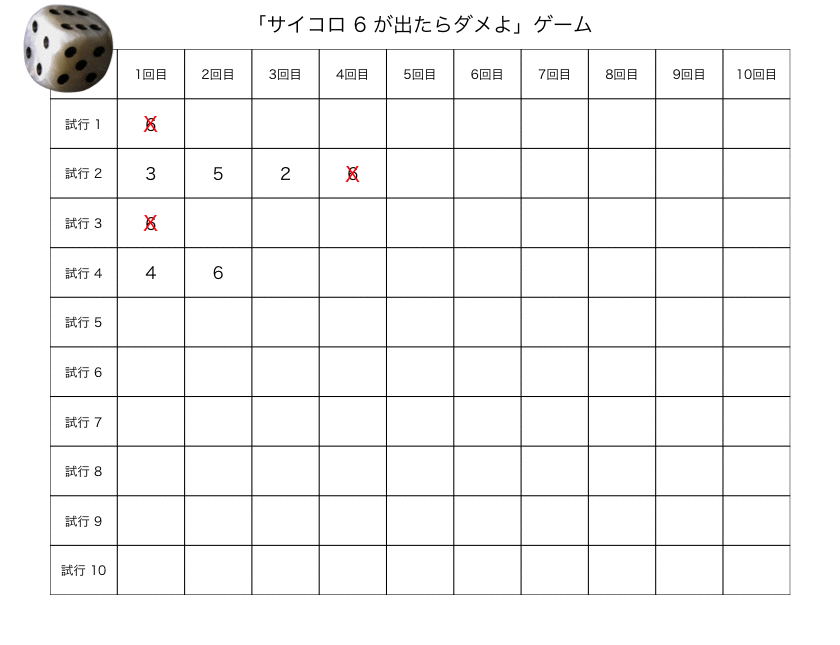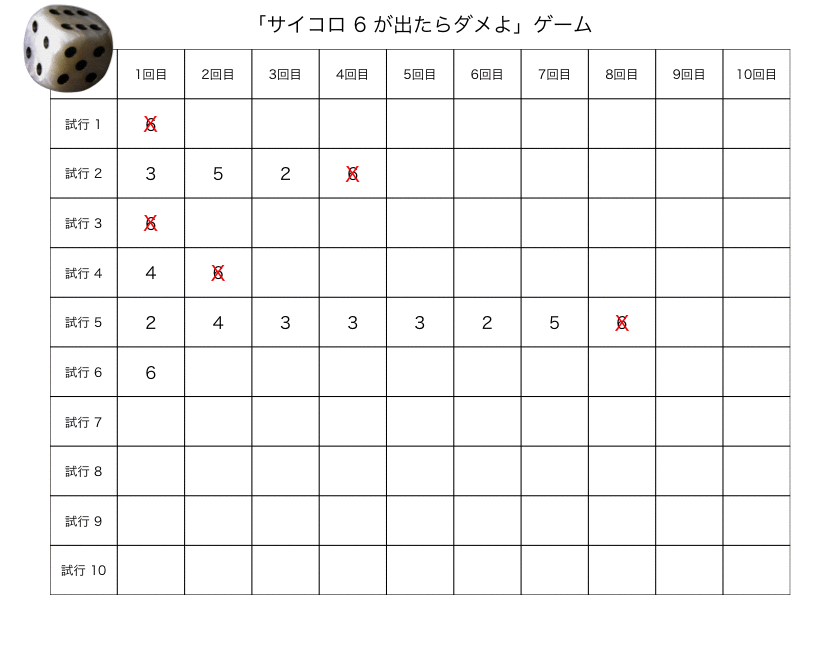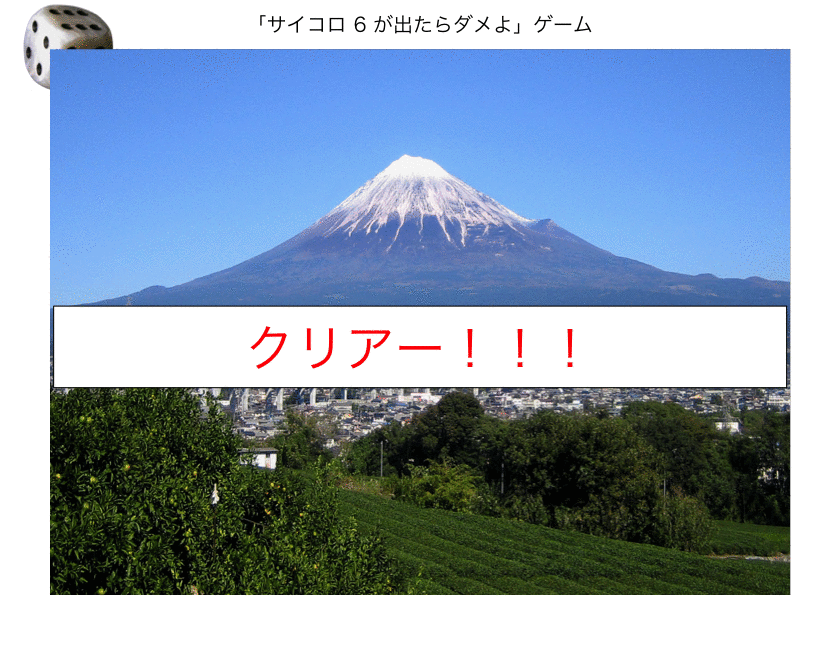
デフォルト設定だと、6の目が出ずに、サイコロを10回振り切れれば、ゲーム・クリアという設定にしてみた。
#下記のSaikoroGame関数をコピペせずに、Gitからsourceする source("https://gist.githubusercontent.com/kumeS/a4c708ed1a9b73e886313389980c4793/raw/b2f9dab698cb3332ff835fe8a8f7d9cd1fd40fcd/SaikoroGame.R") #実行01: デフォ実行 + 保存 SaikoroGame()
実行結果(1)
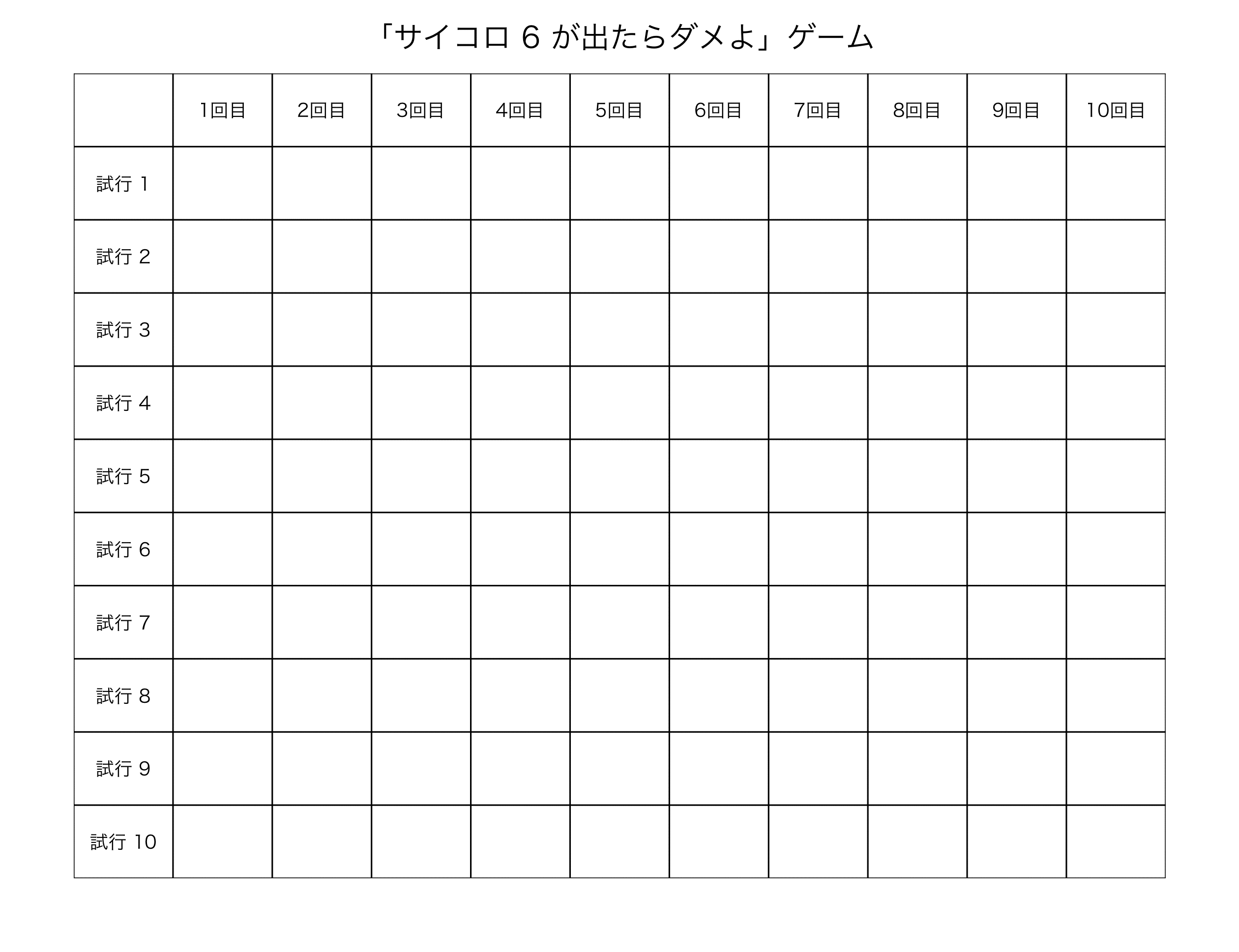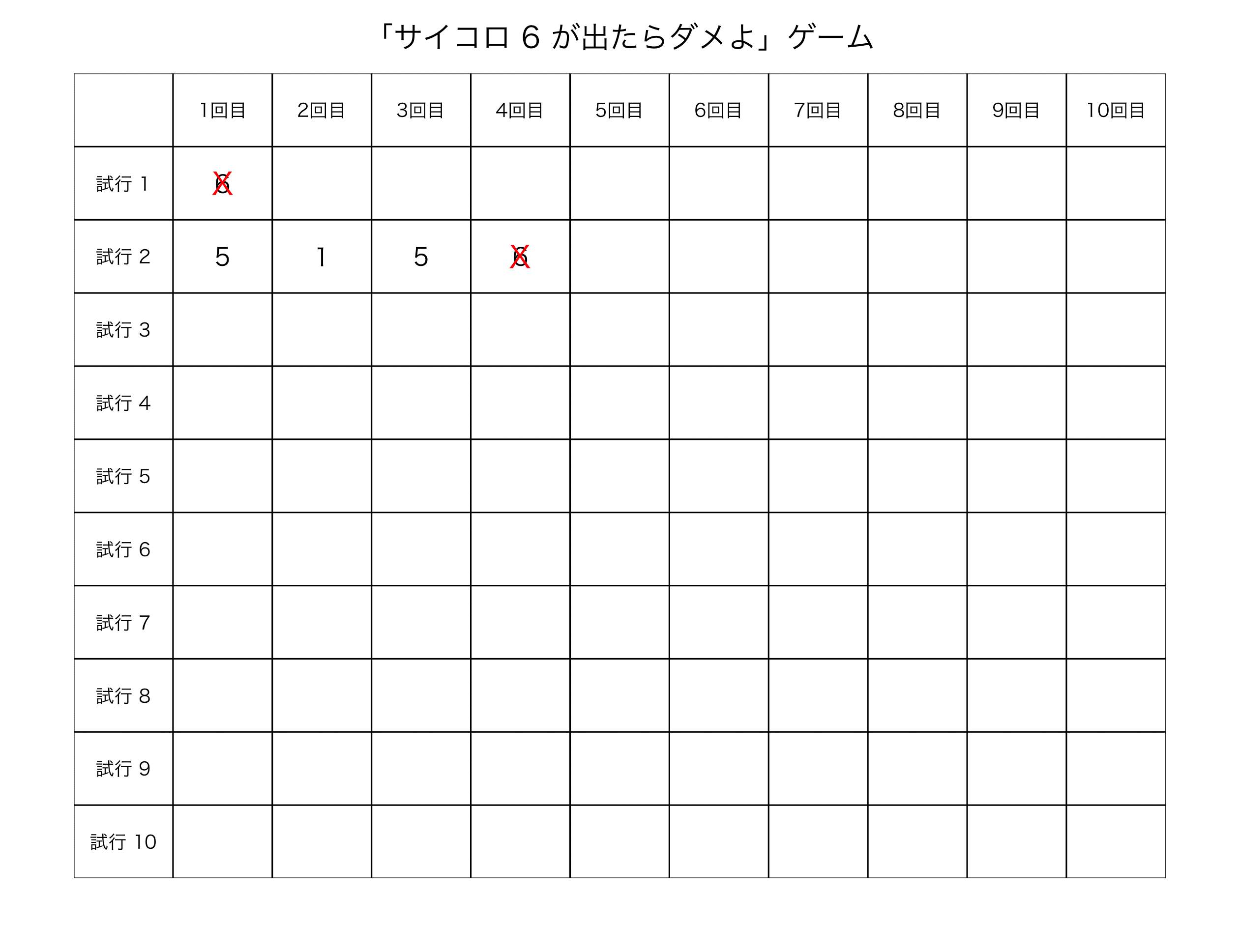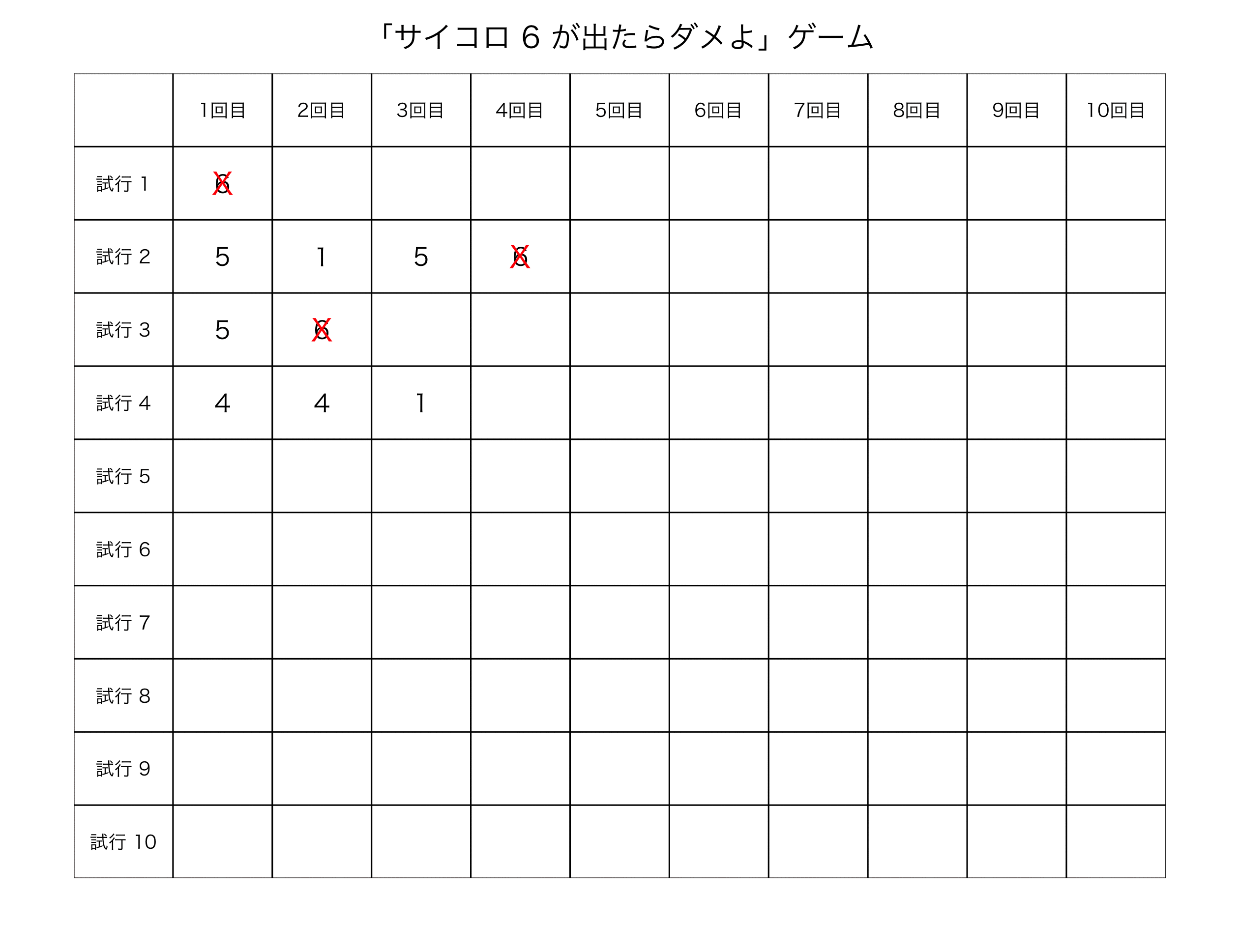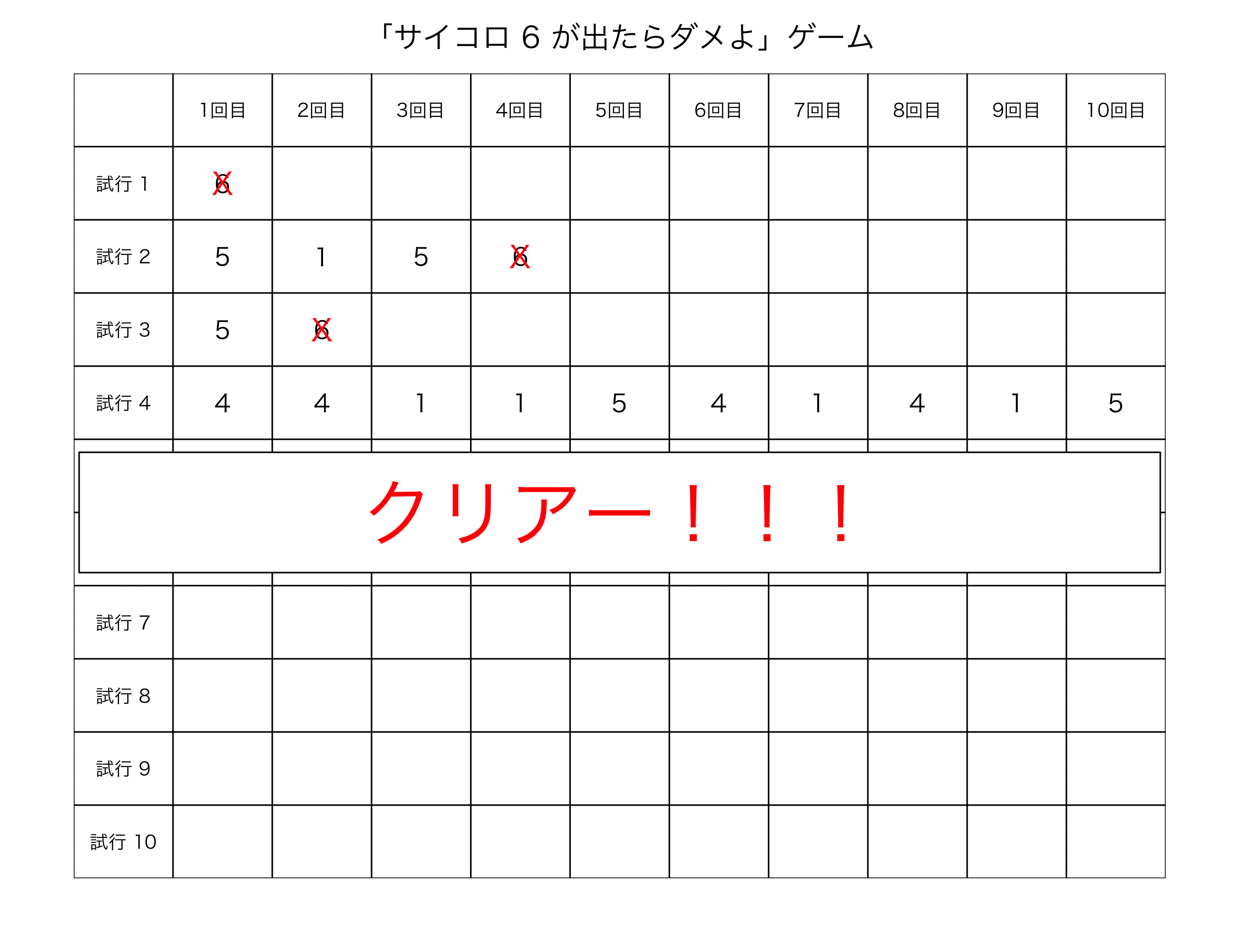
#実行02: おまけ写真付き + 保存 SaikoroGame(Saikoro=T) #save実行時(GIF動画作成)には、事前に、ImageMagickをインストール #save機能は、Macのみ実行可能である #SaikoroGame(save=T) #SaikoroGame(Saikoro=T, save=T)
実行結果(2)
(GIF動画作成の場合)ImageMagickのインストール
ターミナルを起動して、brewコマンドで、ImageMagickをインストールする。
brew install imagemagick
過去の参考記事
SaikoroGame 関数
#パッケージのインストール・ロード if(!require("plotrix")){install.packages("plotrix")} if(!require("EBImage")){install.packages("EBImage")} if(!require("beepr")){install.packages("beepr")} library(plotrix) library(EBImage) library(beepr) #環境変数を消す rm(list=ls()) #関数の作成 SaikoroGame <- function(N=6, save=F, Saikoro=F, Sound=F){ #変数の準備 a = c(1:10) #オプション設定 par(mfrow = c(1,1), family="HiraKakuProN-W3", cex=1, mgp=c(2.5, 1, 0), mai=c(0.5, 0.5, 0.5, 0.5), xpd=F) #空枠の作成 plot(a, a, type="n", axes=F, xlab=NA, ylab=NA, xlim=c(0,11), ylim=c(0,11), main=paste0("「サイコロ ", N, " が出たらダメよ」ゲーム"), xaxs="i", yaxs="i") #区切り線の作成 abline(h=a); abline(h=c(0, 11)) abline(v=a); abline(v=c(0, 11)) if(Saikoro){ ff <- as.raster(EBImage::readImage("https://kumes.github.io/Blog/SaikoroGame/Dice.png", type = "png")) par(xpd=T) rasterImage(ff, xleft=-0.5, xright=1, ybottom=10, ytop=12) par(xpd=F) } #試行回数、回数を記載 text(a+0.5, 10.5, labels=paste0(a, "回目"), cex=0.75) text(0.5, a-0.5, labels=rev(paste0("試行 ", a)), cex=0.75) #試行回数 n <- 0 #ゲーム実行 repeat{ n <- n + 1 x <- 0 Fin <- FALSE repeat{ if(save){ DPI <- ifelse(Saikoro, 100, 300) quartz.save(file = paste0("./SaikoroGame_", formatC(n, width=2, flag=0), "_", formatC(x, width=2, flag=0), ".png"), type = "png", dpi = DPI)} Sys.sleep(1) #回数 x <- x + 1 #1〜6までの一様分布 b <- as.integer( runif(1, min = 1, max = 7) ) if(b != N){ text(x + 0.5, 10.5 - n, labels = b ) Sys.sleep(0.5); if(Sound){beepr::beep(2)} if(save){ DPI <- ifelse(Saikoro, 100, 300) quartz.save(file = paste0("./SaikoroGame_", formatC(n, width=2, flag=0), "_", formatC(x, width=2, flag=0), ".png"), type = "png", dpi = DPI)} }else{ text(x + 0.5, 10.5 - n, labels = b ) if(save){ DPI <- ifelse(Saikoro, 100, 300) quartz.save(file = paste0("./SaikoroGame_", formatC(n, width=2, flag=0), "_", formatC(x, width=2, flag=0), "_a.png"), type = "png", dpi = DPI)} Sys.sleep(0.5) text(x + 0.5, 10.5 - n, labels = "X", col="red", cex=1.25 ) if(Sound){beepr::beep(9)} if(save){ DPI <- ifelse(Saikoro, 100, 300) quartz.save(file = paste0("./SaikoroGame_", formatC(n, width=2, flag=0), "_", formatC(x, width=2, flag=0), "_b.png"), type = "png", dpi = DPI)} break } if(x == 10){ if(Saikoro){ v <- as.character(as.integer( runif(1, min = 1, max = 11))) switch (v, "1" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/c/c4/Suwa-ko_firework_20080815_02.jpg"; type <- "jpg"'))), "2" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/3/3e/MtFuji_FujiCity.jpg"; type <- "jpg"'))), "3" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/5/52/Supermario_Kungsbacka.jpg"; type <- "jpg"'))), "4" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/f/f5/Korean.food-Bibimbap-02.jpg"; type <- "jpg"'))), "5" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/7/75/Ayiin_2020-01-03.jpg"; type <- "jpg"'))), "6" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/2/2b/Lysozyme.png"; type <- "png"'))), "7" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/a/ae/Aomori_Bay_Asamushi_Onsen_Japan02bs5.jpg"; type <- "jpg"'))), "8" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/6/68/Staphylococcus_aureus%2C_50%2C000x%2C_USDA%2C_ARS%2C_EMU.jpg"; type <- "jpg"'))), "9" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/5/57/Red_Fuji_southern_wind_clear_morning.jpg"; type <- "jpg"'))), "10" = eval(parse(text = paste0('url <- "https://upload.wikimedia.org/wikipedia/commons/9/97/The_Earth_seen_from_Apollo_17.jpg"; type <- "jpg"'))) ) ff <- as.raster(EBImage::readImage(url, type = type)) rasterImage(ff, xleft=0, xright=11, ybottom=0, ytop=11) if(save){ DPI <- ifelse(Saikoro, 100, 300) quartz.save(file = paste0("./SaikoroGame_", formatC(n, width=2, flag=0), "_", formatC(x+1, width=2, flag=0), "_a.png"), type = "png", dpi = DPI)} } Sys.sleep(1) plotrix::boxed.labels(5.5, 5, "クリアー!!!", col="red", cex=3, bg = "white", xpad = 1.5, ypad = 1.5) if(Sound){beepr::beep(8)} if(save){ DPI <- ifelse(Saikoro, 100, 300) quartz.save(file = paste0("./SaikoroGame_", formatC(n, width=2, flag=0), "_", formatC(x+1, width=2, flag=0), "_b.png"), type = "png", dpi = DPI)} options(show.error.messages = F) Fin <- TRUE break }} if(Fin){break} if(n == 10){ if(Saikoro){ url <- "https://upload.wikimedia.org/wikipedia/commons/a/ad/Seikima-II_20100704_Japan_Expo_60.jpg" type <- "jpg" ff <- as.raster(EBImage::readImage(url, type = type)) rasterImage(ff, xleft=0, xright=11, ybottom=0, ytop=11)} if(save){ DPI <- ifelse(Saikoro, 100, 300) quartz.save(file = paste0("./SaikoroGame_", formatC(n, width=2, flag=0), "_", formatC(x+1, width=2, flag=0), ".png"), type = "png", dpi = DPI)} Sys.sleep(0.5) plotrix::boxed.labels(5.5, 2.5, "クリアーならず!!", col="blue", cex=3, bg = "white", xpad = 1.25, ypad = 1.5) Sys.sleep(0.5) if(Sound){beepr::beep(9); beepr::beep(9); beepr::beep(9)} if(save){ DPI <- ifelse(Saikoro, 100, 300) quartz.save(file = paste0("./SaikoroGame_", formatC(n, width=2, flag=0), "_", formatC(x+2, width=2, flag=0), ".png"), type = "png", dpi = DPI)} break }} if(save){ message(paste0("Current directory: ", getwd())) len <- length(list.files(pattern="Animation_SaikoroGame")) message(paste0("Save start !!: ", formatC(len+1, width=2, flag=0))) Sys.sleep(0.2) system(paste0("convert -delay 100 -loop 10 ./SaikoroGame_*.png ./Animation_SaikoroGame", formatC(len+1, width=2, flag=0), ".gif")) Sys.sleep(0.2) system("rm -rf ./SaikoroGame_*.png") message("Save finished !!") }else{message("Finished !!")} }
補足
6以外が10回出続ける確率
ちなみに、6以外が10回出続ける確率は、
(5/6)^10 0.1615056
アガリの確率は、結構高い。
list.files実行について
なぜだか、ファイル数の長さである、変数 len にファイル数と一致する数値が入らなかった。
今回は、その前に、何かしらの実行(ex. message(paste0("Current directory: ", getwd())))を入れてあげるとうまく解決した。








