
- はじめに
- 【初級編】Google サーチのキーワード検索でURL一覧を得る + 全URLをブラウザで開く方法
- 【初級編】特定のPDFファイルをダウンロードする方法
- 【一般資料の検索編】Google サーチのキーワード検索でURL一覧(.pdf)を得て、そのPDFファイルをダウンロードする方法
- 【学術資料の検索編】Google scholarのキーワード検索でURL一覧(.pdf)を得て、そのPDFファイルをダウンロードする方法
- Webスクレイピングについての関連図書
- まとめ
- 参考資料
はじめに
Webスクレイピングとは、Webサイトから情報を抽出して、その情報を格納・分析可能な構造化データへと変換する技術を意味するようだ*1。
本記事では、RからWebスクレイピングで、 キーワード検索してヒットしたURLやPDFファイルを自動取得する方法を紹介します。
普段から、Googleサーチで情報検索したり、 論文や文献のPDFファイルを探したりしているのではないかと思います。
ユーザーの検索履歴などがトラッキングされ、 それに合わせて情報が提示される昨今、、、 もう、Googleサーチですら面倒だと思いませんか。
まぁ、少し譲歩して、 「R上から検索語を入れて数十ファイルをダウンロードできる」とか 「検索語を入れたバッチファイルをダブルクリックしたら、どんどん情報が得られる」とか くらいなら、まだ許容できるとか思えませんか。
序論はこれくらいにして、早速、R言語でスクリプトを実装してみることにします。
今回は、R上からGoogleのWeb検索をして、URL一覧やPDFファイルをダウンロードするところを扱ってみます。
ライブラリとかの設定
今回のスクリプトを実行するのに必要なライブラリをダウンロード・ロードします。
#組み込みライブラリ #library(utils) # rvest: Easily Harvest (Scrape) Web Pages install.packages("rvest") library(rvest) # xml2: Parse XML install.packages("xml2") library(xml2) #magrittr: A Forward-Pipe Operator for R install.packages("magrittr") library(magrittr)
【初級編】Google サーチのキーワード検索でURL一覧を得る + 全URLをブラウザで開く方法
ここでは、RからGoogle検索を実施して、結果をURL一覧として取得してみます。
まずは、「生化学」を検索語として入力して、google サーチ URLのパーセントエンコードを行います。
#検索語 query <- "生化学" #URLのパーセントエンコード url <- URLencode(paste0("https://www.google.com/search?q=", query))
次に、そのURLで表示されるHTML記述を読み込んで、 その結果をパースしてベクトルの形にして、 必要なところだけを選別して、データ化していきます。
以下の6行でそれを実行すると、page にはURL一覧がベクトルとして得られます。
#Google検索する page <- xml2::read_html(url) %>% rvest::html_nodes("a") %>% rvest::html_attr("href") %>% .[startsWith(., "/url?q=")] %>% sub("^/url\\?q\\=(.*?)\\&sa.*$", "\\1", .) %>% .[!startsWith(., "https://accounts.google.com")] #URL一覧の表示 page # [1] "https://ja.wikipedia.org/wiki/%25E7%2594%259F%25E5%258C%2596%25E5%25AD%25A6" # [2] "http://www.sc.fukuoka-u.ac.jp/~bc1/Biochem/index1.htm" # [3] "http://www.sc.fukuoka-u.ac.jp/~bc1/Biochem/biochem1.htm" # [4] "http://www.sc.fukuoka-u.ac.jp/~bc1/Biochem/biochem2.htm" # [5] "http://www.sc.fukuoka-u.ac.jp/~bc1/Biochem/biochem5.htm" # [6] "http://www.sc.fukuoka-u.ac.jp/~bc1/Biochem/hormone.htm" # [7] "https://www.juntendo.ac.jp/graduate/laboratory/labo/seikagaku_seitaibogyo/html/index_j.html" # [8] "https://ja.wikipedia.org/wiki/%25E7%2594%259F%25E5%258C%2596%25E5%25AD%25A6" # [9] "https://www.seikagaku.co.jp/ja/index.html" # [10] "https://www.seikagaku.co.jp/ja/corporate/corporate.html" # [11] "https://www.seikagaku.co.jp/ja/corporate.html" # [12] "https://www.seikagaku.co.jp/ja/ir.html" # [13] "https://www.seikagaku.co.jp/ja/recruit.html" # [14] "http://www.jbsoc.or.jp/member_only" # [15] "https://seikagaku.jbsoc.or.jp/" # [16] "https://kotobank.jp/word/%25E7%2594%259F%25E5%258C%2596%25E5%25AD%25A6-85551" # [17] "http://www.jaob.jp/field/biochemistry.html" # [18] "http://sekigin.jp/science/chem/chem_07.html" # [19] "https://www.niid.go.jp/niid/ja/from-biochem/3263-2013-02-25-07-34-02.html"
次に、得られたURL一覧をブラウザで開いてみます。
URLが19個もあるので、個別で開くのは手間ですよね。そこで、forループで開いてみます。
for(n in seq_len(length(page))){ browseURL(url=page[n]) }
いちおう、これら処理を関数化してみました。
gistにgoogleSearch_function.Rというファイル名でアップしているので、それをソースします。
googleSearchPage関数を実行すると、上述と同じ結果になるはずです。
source("https://gist.githubusercontent.com/kumeS/ef4d750a191b847174b3b93a4b8391c9/raw/eb5510fa87f262dc51257948b4899d313681081d/googleSearch_function.R") a <- googleSearchPage(Query="生化学", Open=F) print(a) #そのままブラウザで開く googleSearchPage(Query="生化学", Open=T)
【初級編】特定のPDFファイルをダウンロードする方法
あるPDFファイルのURLを与えて、ダウンロードする事例を考えてみます。
例えば、「日本生化学会65年の歩み」PDFファイルのURLを、
utils::download.fileで読み込むと、
そのPDFファイルが作業ディレクトリ内にダウンロードされます。
以下が、実行コマンドとなる。
# 日本生化学会65年の歩み url <- "http://www.jbsoc.or.jp/seika/wp-content/uploads/2013/03/ayumi-1990-.pdf" # pdf_file_01 としてファイル保存 download.file(url = url, destfile = "pdf_file_01.pdf", mode="wb") dir()
これまでが初級編で、次から少し応用的な内容を扱います。
【一般資料の検索編】Google サーチのキーワード検索でURL一覧(.pdf)を得て、そのPDFファイルをダウンロードする方法
ここからが本題で、実際に、Google サーチのキーワード検索で得たPDFファイルのURLから自動ダウンロードをおこなってみます。
まずは、gistのRファイルをソースします*2。
#2020/12/21修正 source("https://gist.githubusercontent.com/kumeS/ef4d750a191b847174b3b93a4b8391c9/raw/3ef33d16ea985873b9b7337d4d74affff0aa2d38/googleSearch_function.R")
PDFダウンロードの処理は関数化してあるので、
googleSearchPDF を実行するだけでできます*3*4。
ここでは、「生化学」を検索語として、Google検索でPDFファイルのURLを得たり、実際のPDFファイルをダウンロードしたりしてみます。
#キーワード検索をして、PDFファイルのURLを得る query <- "生化学" b1 <- googleSearchPDF(Query=query, Download=F) b1 #$生化学 #[1] "http://www.tkd-pbl.com/files/mcmurry_seikagakuhannoukikou_2nd.pdf" #[2] "https://www.nsh.gr.jp/wp-content/uploads/850239f12471ab887860303771e1746f-1.pdf" #[3] "https://www.mitsuihosp.or.jp/media/seikagaku.pdf" #[4] "https://www.dent.nihon-u.ac.jp/uploads/files/2561_%25E7%2594%259F%25E5%258C%2596%25E5%25AD%25A6.pdf" #[5] "https://www.iwate-med.ac.jp/wp-content/uploads/7f57dc685ba560c4e88d7590b8ae8931.pdf" #[6] "http://www.f.kpu-m.ac.jp/k/jkpum/pdf/124/124-12/kantougen12.pdf" #[7] "http://www.hinohp.com/files/23603.pdf" #[8] "https://nijihashi-clinic.jp/wpadm/wp-content/themes/nijijp/img/checkup/examination.pdf" #キーワード検索をして、PDFファイルをダウンロードする googleSearchPDF(Query=query, Download=T)
こんな感じで、PDFファイルがダウンロードされます。
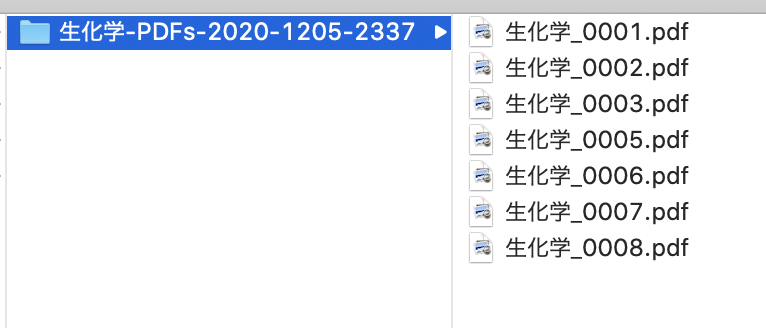
また、他の検索方法にも対応していて、 例えば、ヒットした検索ページ数を多くしたり、 複数の検索語を与えて別の検索が実施できたりします。
以下に関数の引数も簡単に説明してあります。
googleSearchPDF関数の引数説明 Query: 1つ以上の文字列ベクトル Pages: 検索するページ数 com: TRUEなら"https://www.google.com"、FALSEなら"www.google.co.jp"を検索する。 Download: PDFファイルをダウンロードするかしないか
それでは、検索ページ数を増やして実行してみると。
#検索ページ数 3 での検索結果 b3 <- googleSearchPDF(Query=query, Pages=3, Download=F) b3 #$生化学 # [1] "http://www.tkd-pbl.com/files/mcmurry_seikagakuhannoukikou_2nd.pdf" # [2] "https://www.nsh.gr.jp/wp-content/uploads/850239f12471ab887860303771e1746f-1.pdf" # [3] "https://www.mitsuihosp.or.jp/media/seikagaku.pdf" # [4] "https://www.dent.nihon-u.ac.jp/uploads/files/2561_%25E7%2594%259F%25E5%258C%2596%25E5%25AD%25A6.pdf" # [5] "https://www.iwate-med.ac.jp/wp-content/uploads/7f57dc685ba560c4e88d7590b8ae8931.pdf" # [6] "http://www.f.kpu-m.ac.jp/k/jkpum/pdf/124/124-12/kantougen12.pdf" # [7] "http://www.hinohp.com/files/23603.pdf" # [8] "https://nijihashi-clinic.jp/wpadm/wp-content/themes/nijijp/img/checkup/examination.pdf" # [9] "https://ymc.yuuai.or.jp/pdf/department/biochemical_test.pdf" #[10] "http://www.hospital.kasai.hyogo.jp/04sinr/04kensa/10-1_%25E7%2594%259F%25E5%258C%2596%25E5%25AD%25A6%25E6%25A4%259C%25E6%259F%25BB.pdf" #[11] "http://www.kyoto1-jrc.org/files/pdf/shinryo-section/equipment/koumoku01.pdf" #[12] "http://www.jccls.org/seminar_record/2013_2/4.pdf" #[13] "https://tokyo-hp.hosp.go.jp/bumon/rinken/pdf/kadai_seikagaku.pdf" #[14] "http://www.amh.ako.hyogo.jp/department/rinsho_kensa/pdf/kensa_setumei.pdf" #[15] "http://www.otaru-general-hospital.jp/kango-gakuin/wp-content/uploads/sites/2/2020/09/03d0e203c4001d6bec013c00f87f64bc.pdf" #[16] "http://www.falco.co.jp/rinsyo/contents/pdf/18102.pdf" #[17] "http://www.lans-inc.co.jp/inspection/data/seikagakukensa1.pdf" #[18] "https://www.mhlw.go.jp/file/05-Shingikai-10803000-Iseikyoku-Ijika/0000128982.pdf" #[19] "http://www.naramed-u.ac.jp/~bioch/H28CoreCurri.pdf" #[20] "http://www.kyobiken.or.jp/system/site_data/site_0/page_573/version_6/file/0020.pdf" #[21] "http://www.jbsoc.or.jp/seika/wp-content/uploads/2014/07/85-12-01.pdf" #[22] "https://www.sysmex.co.jp/products_solutions/library/journal/vol17_no2/bfvlfm000000cnu7-att/Vol17_2_07.pdf" #[23] "https://sahswww.med.osaka-u.ac.jp/jpn/guide2/doc/iryogijyutu-syokaki.pdf" #[24] "https://www.akita-eiyo.ac.jp/eiyo-cms/assets/uploads/2020/10/eiyo2020_1_33.pdf" #[25] "https://www.fra.affrc.go.jp/bulletin/bull/bull-b5/12.pdf" #[26] "http://zen.shinshu-u.ac.jp/modules/0098000001/main/0098000001.pdf" #[27] "https://www.med.nagoya-u.ac.jp/medlib/holding/suisen/03seika.pdf" #[28] "https://www.fukushihoken.metro.tokyo.lg.jp/iryo/sonota/eiseikensajo/jigyouhoukokusho.files/03.pdf"
次に、検索語を複数(ex. 電子顕微鏡 と 急性白血病)にして検索したら、
#複数の検索語で検索した結果 query2 <- c("電子顕微鏡", "急性白血病") c1 <- googleSearchPDF(Query=query2, Download=F) c1 #$電子顕微鏡 #[1] "https://www.jeol.co.jp/words/semterms/sem-a_z.pdf" #[2] "https://www.sbj.or.jp/wp-content/uploads/file/sbj/9107/9107_yomoyama(1).pdf" #[3] "https://www.jim.or.jp/journal/m/pdf3/58/05/261.pdf" #[4] "http://sts.kahaku.go.jp/diversity/document/system/pdf/041.pdf" #[5] "https://www.eiken.co.jp/uploads/modern_media/literature/MM1302_04.pdf" #[6] "https://www.r-ccs.riken.jp/r-ccssite/wp-content/uploads/2018/06/8ce9efad77134c7f18a338b8c7b36e66.pdf" #[7] "http://www008.upp.so-net.ne.jp/earth-sc/sem.pdf" #[8] "https://www.library.osaka-u.ac.jp/doc/LS_20170621_micro.pdf" #$急性白血病 # [1] "http://www.med.osaka-cu.ac.jp/labmed/hino.pdf" # [2] "http://www.med.osaka-cu.ac.jp/labmed/AML.pdf" # [3] "https://www.hamanomachi.jp/shinryou/docs/gan_shinryou_shikkanbetsu_hakketsu.pdf" # [4] "https://www.ncc.go.jp/jp/ncch/clinic/stem_cell_transplantation/stem_cell_transplantation02.pdf" # [5] "https://www.mhlw.go.jp/topics/2009/05/dl/tp0521-1a_0027.pdf" # [6] "http://www.saitama-med.ac.jp/lecture/materials/35-H2001-2.pdf" # [7] "http://www.jshem.or.jp/uploads/files/58-08_p1086-1093.pdf" # [8] "https://hospital.city.sendai.jp/pdf/pdf_gan02.pdf" # [9] "http://kcch.kanagawa-pho-m.jp/event/files/kouza20200118-02.pdf" #[10] "http://kenchu.ipch.jp/other/doc/seijinileu.pdf"
【学術資料の検索編】Google scholarのキーワード検索でURL一覧(.pdf)を得て、そのPDFファイルをダウンロードする方法
あと、Google scholar検索バージョンも作成してみた。
ただ、このバージョンは1ページ目の情報しか取得できずなので、 情報量としてはまだイマイチで改善余地がありそう。
とりあえず、googleScholarSearchPDF関数を実行してみる。
query3 <- c("Electron microscopy", "Deep learning") d <- googleScholarSearchPDF(Query=query3, Download=F) d #$`Electron microscopy` #[1] "https://www.academia.edu/download/57247294/R._Egerton-Physical_Principles_of_Electron_Microscopy_An_Introduction_to_TEM_SEM_and_AEM-Springer_2008.pdf" #[2] "https://link.springer.com/content/pdf/10.1007/978-3-319-39877-8.pdf" #[3] "https://rupress.org/jem/article-pdf/95/3/285/556608/285.pdf" #[4] "https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2106477/pdf/697.pdf" #$`Deep learning` #[1] "https://synapse.koreamed.org/upload/SynapseData/PDFData/1088HIR/hir-22-351.pdf" #[2] "https://s3.us-east-2.amazonaws.com/hkg-website-assets/static/pages/files/DeepLearning.pdf" #[3] "https://www.icpme.us/courses/CIBC_PDF/4.1%20CAD_Radiomics_and%20AI%20in%20Breast%20Imaging_Giger.pdf" #[4] "http://bigr.io/wp-content/uploads/2017/09/BigR.io-Deep-Learning-Image-and-Video-Recognition.pdf" #[5] "http://papers.nips.cc/paper/5025-predicting-parameters-in-deep-learning.pdf" #[6] "https://www.academia.edu/download/58251403/neural_networks_and_deep_learning.pdf"
まぁ、こんな感じで、"Electron microscopy"と"Deep learning"でヒットしたPDFファイルURLの一覧が得られる。
Webスクレイピングについての関連図書
Webスクレイピングの関連図書を列挙しておきます。


まとめ
R言語からGoogleサーチを実行して、URL一覧の取得とかPDFファイル取得とかをやってみた。
RとGoogle検索の組み合わせでも、十分にWebスクレイピングができそうではある。
ただ今のところ、Google Scholarをうまく活用するにはもう少し検討が要りそうな感じがする。
今後、wikipediaページのWebスクレイピングなど、話題も取り上げようと思っている。