
はじめに
最近、数GBを超えるテキストデータを扱うようになり、今更ながら、Rのファイル読み込み関数の速度比較について一度検討してみた。
今回、以下の3つのファイル読み込み関数について調査してみた。
実行環境
macOS Catalina (10.15.4) R version 3.6.3 (2020-02-29)
検証用のファイル生成
検証用のファイルとしては、適当な文字列が適当に改行されて、10億行くらいあるファイル(.txt あるいは.csv)が用意できればと考えている。
まず、文字列生成について調べてみた。最初に見つかったのが、opensslコマンドを使う方法である。
opensslコマンドを用いた、ランダム文字列の生成
ランダム文字列を生成する、opensslコマンドの基本文法としては以下のようだ。
openssl rand [進数] [任意のバイト数]
進数のオプション:
-hex : 16進数
-base64 : 64進数
実際に、opensslで文字列生成をやってると、
openssl rand -hex 10 3fd8220419ed7c62043c openssl rand -base64 10 k/ROtoo/l2k7aw==
出力を見た感じ、Rで読み込むなら、-hex(16進数) が良さそうだ。
少し 長めの文字列も出力してみると
time openssl rand -hex 5000000 > test.txt real 0m0.833s user 0m0.812s sys 0m0.017s ## ファイル内の文字数のカウント wc -m test.txt 10000001 test.txt ## 1文字ずつで改行する time fold -w 1 test.txt > testR.txt real 0m1.315s user 0m1.276s sys 0m0.031s
testR.txtファイルで、約1000万文字(行)、20MBほどのファイルが生成できた。
ただ、これだと、生成速度が若干遅いので、別の方法も検討してみる。
echoとtrコマンドを用いた文字列の生成
echoとtrコマンドを組み合わせると、改行した文字列が作れるようだ。例えば、こんな感じ
echo 'helloworld'{1..5} | tr ' ' '\n' helloworld1 helloworld2 helloworld3 helloworld4 helloworld5
まぁ、いま思うと、連番の数字だけでも良いように思う。
'helloworld'を消して実行してみると
time echo {1..10000000} | tr ' ' '\n' > test1.txt real 0m22.817s user 0m23.285s sys 0m0.614s ## 行数をカウントしてみる wc -l test1.txt 10000000 test1.txt
1000万行、79MBほどのファイルが生成できた。
こっちも、生成に結構時間がかかる。
seqコマンドを用いた連番数字の生成
単純に、連番数字の生成の場合なら、seqというコマンドがあるようだ。
コマンドの文法もシンプルで良い。
seq 5 1 2 3 4 5
また、同じく連番数字で2000万行を生成してみたが、、結構速い。「echoとtr」よりも10倍くらい速い。
time seq 10000000 > test2.txt real 0m2.297s user 0m2.161s sys 0m0.122s wc -l test2.txt 10000000 test2.txt
114MBほどのファイルが生成できた。
echoとtrコマンドの時より、ファイルサイズが大きいのが気がかりだが、とりあず速いので、seqコマンドでやってみる。
seqコマンドを用いた検証用ファイルの生成
以下、time seq [行数] > [ファイル名].txt コマンドで実行した結果である。
| ファイル名 | 行数 | サイズ(約) | real時間 |
|---|---|---|---|
| Seq01.txt | 1000万 | 114MB | 0m2.478s |
| Seq02.txt | 2000万 | 233MB | 0m4.548s |
| Seq04.txt | 4000万 | 471MB | 0m9.150s |
| Seq06.txt | 6000万 | 708MB | 0m13.319s |
| Seq08.txt | 8000万 | 946MB | 0m18.095s |
| Seq10.txt | 1億 | 1.18GB | 0m22.223s |
| Seq15.txt | 1.5億 | 1.78GB | 0m31.878s |
| Seq30.txt | 3.0億 | 3.56GB | 1m3.527s |
検証用ファイルが生成できたところで、ようやくRでの読み込みをやってみる。まずは、、、
Rでのファイル読み込み検証
utils::read.table関数でのファイル読み込み
R上で、read.table関数で読み込んでみて、ちゃんと読み込めているかをしてみる。((いちおう、dim関数とtail関数で確かめた(省略)。))
## 有効数字の設定 options(digits=7) ## 指数表現の設定 options(scipen=100) ##読み込み実行 system.time(ur_Seq01 <- read.table("./Seq01.txt")) # ユーザ システム 経過 # 5.683 0.198 5.895 system.time(ur_Seq02 <- read.table("./Seq02.txt")) # ユーザ システム 経過 # 8.641 0.312 8.991 system.time(ur_Seq04 <- read.table("./Seq04.txt")) # ユーザ システム 経過 # 15.087 0.568 15.700 system.time(ur_Seq06 <- read.table("./Seq06.txt")) # ユーザ システム 経過 # 22.121 0.840 23.085 system.time(ur_Seq08 <- read.table("./Seq08.txt")) # ユーザ システム 経過 # 28.819 1.246 30.322 system.time(ur_Seq10 <- read.table("./Seq10.txt")) # ユーザ システム 経過 # 35.568 1.343 37.051 system.time(ur_Seq15 <- read.table("./Seq15.txt")) # ユーザ システム 経過 # 53.427 2.523 56.541 system.time(ur_Seq30 <- read.table("./Seq30.txt")); tail(ur_Seq30, n=100) # ユーザ システム 経過 # 103.617 6.371 111.173
data.table::fread関数でのファイル読み込み
data.tableパッケージをインストールして、読み込む。
if(!require("data.table")){install.packages("data.table")}; library(data.table) #要求されたパッケージ data.table をロード中です #data.table 1.12.8 using 4 threads (see ?getDTthreads). Latest news: r-datatable.com
早速、fread関数を試してみる。
##読み込み実行 system.time(df_Seq01 <- fread("./Seq01.txt")) # ユーザ システム 経過 # 0.296 0.083 0.215 system.time(df_Seq02 <- fread("./Seq02.txt")) # ユーザ システム 経過 # 0.513 0.163 0.406 system.time(df_Seq04 <- fread("./Seq04.txt")) # ユーザ システム 経過 # 0.992 0.306 0.728 system.time(df_Seq06 <- fread("./Seq06.txt")) # ユーザ システム 経過 # 1.507 0.502 1.081 system.time(df_Seq08 <- fread("./Seq08.txt")) # ユーザ システム 経過 # 2.133 0.790 1.533 system.time(df_Seq10 <- fread("./Seq10.txt")) # ユーザ システム 経過 # 2.597 1.082 2.092 system.time(df_Seq15 <- fread("./Seq15.txt")) # ユーザ システム 経過 # 3.779 1.961 4.028 system.time(df_Seq30 <- fread("./Seq30.txt")) # ユーザ システム 経過 # 7.847 3.987 8.032
readr::read_csv関数でのファイル読み込み
readrパッケージをインストールして、読み込む。
if(!require("readr")){install.packages("readr")}; library(readr) # 要求されたパッケージ readr をロード中です
read_csv関数を試してみる
##読み込み実行 system.time(rr_Seq01 <- read_csv("./Seq01.txt", col_names = F)) # ユーザ システム 経過 # 1.208 0.078 1.290 system.time(rr_Seq02 <- read_csv("./Seq02.txt", col_names = F)) # ユーザ システム 経過 # 2.797 0.310 3.717 system.time(rr_Seq04 <- read_csv("./Seq04.txt", col_names = F)) # ユーザ システム 経過 # 5.614 0.588 7.349 system.time(rr_Seq06 <- read_csv("./Seq06.txt", col_names = F)) # ユーザ システム 経過 # 8.425 0.819 11.102 system.time(rr_Seq08 <- read_csv("./Seq08.txt", col_names = F)) # ユーザ システム 経過 # 11.244 1.147 14.760 system.time(rr_Seq10 <- read_csv("./Seq10.txt", col_names = F)) # ユーザ システム 経過 # 13.981 1.973 21.484 system.time(rr_Seq15 <- read_csv("./Seq15.txt", col_names = F)) # ユーザ システム 経過 # 21.906 3.270 32.043 system.time(rr_Seq30 <- read_tsv("./Seq30.txt", col_names = F)) # ユーザ システム 経過 # 43.632 6.119 63.369
速度比較の結果
ファイルサイズ、読み込み速度の結果を関数ごとにまとめてみる。
| ファイル名 | 行数 | サイズ(約) | read.table | fread | read_csv |
|---|---|---|---|---|---|
| Seq01.txt | 1000万 | 114MB | 5.895 | 0.215 | 1.290 |
| Seq02.txt | 2000万 | 233MB | 8.991 | 0.406 | 3.717 |
| Seq04.txt | 4000万 | 471MB | 15.700 | 0.728 | 7.349 |
| Seq06.txt | 6000万 | 708MB | 23.085 | 1.081 | 11.102 |
| Seq08.txt | 8000万 | 946MB | 30.322 | 1.533 | 14.760 |
| Seq10.txt | 1億 | 1.18GB | 37.051 | 2.092 | 21.484 |
| Seq15.txt | 1.5億 | 1.78GB | 56.541 | 4.028 | 32.043 |
| Seq30.txt | 3.0億 | 3.56GB | 111.173 | 8.032 | 63.369 |
速度比較結果のplotlyグラフ
比較結果をplotlyグラフにしてみる。
## データセットの作成 data <- matrix(c(0.114, 5.895, 0.215, 1.290, 0.233, 8.991, 0.406, 3.717, 0.471, 15.700, 0.728, 7.349, 0.708, 23.085, 1.081, 11.102, 0.946, 30.322, 1.533, 14.760, 1.18, 37.051, 2.092, 21.484, 1.78, 56.541, 4.028, 32.043, 3.56, 111.173, 8.032, 63.369), ncol = 4, byrow = T) ## データフレームへの変換、行列に名前をつける data.df <- data.frame(data) colnames(data.df) <- c("size", "read.table", "fread", "read_csv") rownames(data.df) <- 1:nrow(data.df) data.df # size read.table fread read_csv #1 0.114 5.895 0.215 1.290 #2 0.233 8.991 0.406 3.717 #3 0.471 15.700 0.728 7.349 #4 0.708 23.085 1.081 11.102 #5 0.946 30.322 1.533 14.760 #6 1.180 37.051 2.092 21.484 #7 1.780 56.541 4.028 32.043 #8 3.560 111.173 8.032 63.369 ## plotlyのインストール if(!require("plotly")){install.packages("plotly")}; library(plotly) #plotlyで、マーカー + 折れ線グラフをつくる fig <- plot_ly(data.df, x = ~size, ) fig <- fig %>% add_trace(y = ~read.table, name = 'read.table', mode = 'lines+markers') fig <- fig %>% add_trace(y = ~fread, name = 'fread', mode = 'lines+markers') fig <- fig %>% add_trace(y = ~read_csv, name = 'read_csv', mode = 'lines+markers') fig <- fig %>% layout(xaxis = list(title = 'File size (GB)'), yaxis = list(title = 'Reading time (sec)')) fig
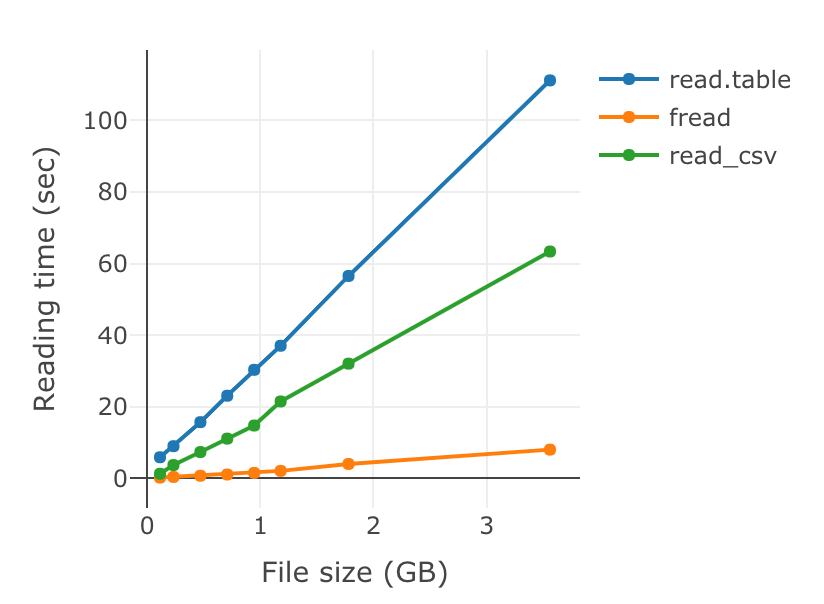
オリジナルHTML図 http://kumeS.github.io/Blog/readingTime/readingTime.html
結果
速いとは聞いていたが、ダントツで、freadでのファイル読み込みが速かった。
補足
読み込みデータフレームの有効数字6桁問題
> ur_Seq01 <- read.table("./Seq01.txt"); tail(ur_Seq01, n=30) V1 9999971 9999970 9999972 9999970 9999973 9999970 9999974 9999970 9999975 9999980 9999976 9999980 9999977 9999980 9999978 9999980 9999979 9999980 9999980 9999980 9999981 9999980 9999982 9999980 9999983 9999980 9999984 9999980 9999985 9999980 9999986 9999990 9999987 9999990 9999988 9999990 9999989 9999990 9999990 9999990 9999991 9999990 9999992 9999990 9999993 9999990 9999994 9999990 9999995 10000000 9999996 10000000 9999997 10000000 9999998 10000000 9999999 10000000 10000000 10000000 > df_Seq01 <- fread("./Seq01.txt"); tail(df_Seq01, n=30) V1 1: 9999970 2: 9999970 3: 9999970 4: 9999970 5: 9999980 6: 9999980 7: 9999980 8: 9999980 9: 9999980 10: 9999980 11: 9999980 12: 9999980 13: 9999980 14: 9999980 15: 9999980 16: 9999990 17: 9999990 18: 9999990 19: 9999990 20: 9999990 21: 9999990 22: 9999990 23: 9999990 24: 9999990 25: 10000000 26: 10000000 27: 10000000 28: 10000000 29: 10000000 30: 10000000 V1 > rr_Seq01 <- read_csv("./Seq01.txt", col_names = F); tail(rr_Seq01, n=30) # A tibble: 30 x 1 X1 <dbl> 1 9999970 2 9999970 3 9999970 4 9999970 5 9999980 6 9999980 7 9999980 8 9999980 9 9999980 10 9999980 # … with 20 more rows
3つの関数の出力とも、一の位が丸まってるので、Rの問題なんだろうか。R version 3.6.3 (2020-02-29)を使ってるのでバージョンの問題なのか。
数字の連番なら、行名を入れればよさそうだけど、、、とりあえず、この問題は今回スキップすることにした。
R上の全てのデータ・変数を消すコマンド
rm(list=ls())
ベクトルのメモリを使い切りましたへの対応
これは、今回でたエラーメッセージである。
エラー: ベクトルのメモリを使い切りました (上限に達した?) Timing stopped at: 0.165 0.002 0.167
これが出てしまう場合は、
cd ~ echo "R_MAX_VSIZE=100Gb" >> .Renviron
と設定すると、ベクトルサイズの上限を変更できる。 実メモリと関係なく、上限メモリを設定するので良いらしい。
また、Rセッションでこの変更を行うには
## 上限32GBの設定 Sys.setenv('R_MAX_VSIZE'=32000000000)
で可能のようだ。