- はじめに
- ひまわり画像をwikipediaからダウンロードして表示する
- RGB画像をヒストグラムで表示する
- グレー画像をヒストグラムで表示する
- RGB画像を各成分に分離して、各画像を表示する
- フィルターを変えて、画像の縮小を行い、結果を比較してみた。
- まとめ
- 参考資料
はじめに
今回は、EBImageとimagerを使った、
R環境での画像処理をいろいろと紹介する。
具体的に、画像ファイルの読み込み・表示、 ヒストグラム表示、グレー画像変換、リサイズ(縮小)とかのプログラムを作成・実行してみた。
はじめに、EBImageとimagerをセットアップする。
パッケージのインストール
#EBImageのインストール install.packages("BiocManager") BiocManager::install("EBImage", force = TRUE) #imagerのインストール install.packages("imager")
ひまわり画像をwikipediaからダウンロードして表示する
download.file関数を使って、Wikipediaからヒマワリの画像をダウンロードする。
そして、EBImageの関数群(readImage & display)を使って、読み込みと表示をやってみる。
#画像のダウンロード download.file(url = "https://upload.wikimedia.org/wikipedia/commons/4/40/Sunflower_sky_backdrop.jpg", destfile = "sunflower.jpg") #EBImageのロードとオプション設定 library(EBImage); options(EBImage.display = "raster") #画像の読み込み Img <- EBImage::readImage(files="./sunflower.jpg", type = "jpg") #画像の表示 EBImage::display(Img) #画像の保存 quartz.save("Img01_sunflower.png", type="png", dpi=100); dev.off()

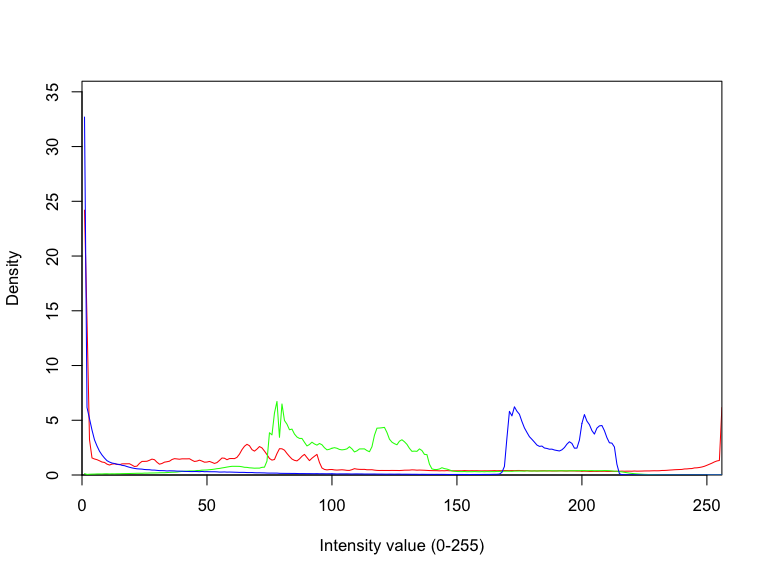
RGB画像をヒストグラムで表示する
次は、RGBのそれぞれの成分で頻度分布を計算して、ヒストグラムとして表示させる。
#クラス表示 str(Img) #Formal class 'Image' [package "EBImage"] with 2 slots # ..@ .Data : num [1:1404, 1:1555, 1:3] 0.00392 0.00392 0.00784 0.00784 0 ... # ..@ colormode: int 2 # ..$ dim: int [1:3] 1404 1555 3 #画像の前処理 a <- hist(unlist(Img[,,1]), breaks=256); dev.off(); a <- a$red$density #Red b <- hist(unlist(Img[,,2]), breaks=256); dev.off(); b <- b$red$density #Green cc <- hist(unlist(Img[,,3]), breaks=256); dev.off(); cc <- cc$red$density #Blue #画像のヒストグラム表示 plot(a, xlim = c(0,256), ylim=c(0, max(c(a, b, cc))*1.1), xlab="Intensity value (0-255)", ylab="Density", xaxs="i", yaxs="i", type="l", col="red") lines(b, col="green") lines(cc, col="blue") quartz.save("Img02_rgb_histo.png", type="png", dpi=100); dev.off()
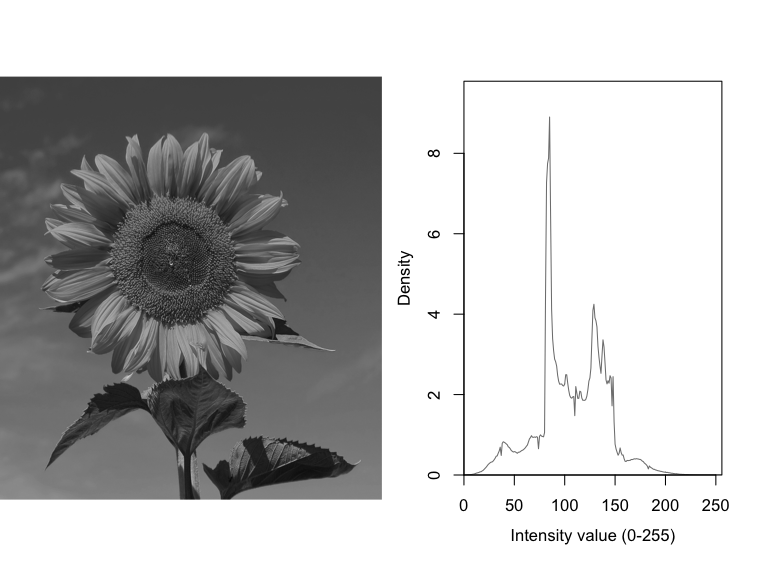
グレー画像をヒストグラムで表示する
ここでは、RGBのカラー画像をグレー画像に変換した後に、頻度分布を計算して、ヒストグラムとして表示させる。
まずは、カラー画像をグレー画像に変換する。
#詳細表示 Img #Image # colorMode : Color # storage.mode : double # dim : 1404 1555 3 # frames.total : 3 # frames.render: 1 # #imageData(object)[1:5,1:6,1] # [,1] [,2] [,3] [,4] [,5] [,6] #[1,] 0.003921569 0.003921569 0.003921569 0.003921569 0.003921569 0.003921569 #[2,] 0.003921569 0.003921569 0.003921569 0.003921569 0.003921569 0.003921569 #[3,] 0.007843137 0.007843137 0.007843137 0.007843137 0.003921569 0.003921569 #[4,] 0.007843137 0.003921569 0.003921569 0.003921569 0.003921569 0.003921569 #[5,] 0.000000000 0.003921569 0.003921569 0.003921569 0.003921569 0.003921569 #グレーに変換 ImgGr <- array(EBImage::channel(Img, "gray"), dim = dim(Img)[1:2]) #詳細表示 ImgGr #Image # colorMode : Grayscale # storage.mode : double # dim : 1404 1555 # frames.total : 1 # frames.render: 1 # #imageData(object)[1:5,1:6] # [,1] [,2] [,3] [,4] [,5] [,6] #[1,] 0.3124183 0.3124183 0.3124183 0.3124183 0.3124183 0.3124183 #[2,] 0.3124183 0.3124183 0.3124183 0.3124183 0.3124183 0.3124183 #[3,] 0.3163399 0.3163399 0.3163399 0.3163399 0.3124183 0.3124183 #[4,] 0.3163399 0.3124183 0.3124183 0.3124183 0.3124183 0.3124183 #[5,] 0.3084967 0.3124183 0.3124183 0.3124183 0.3124183 0.3124183 EBImage::display(ImgGr) quartz.save("Img03_sunflower.png", type="png", dpi=100); dev.off()

次に、グレー画像のヒストグラムも合わせて表示してみる。
#画像の前処理 a <- hist(unlist(ImgGr), breaks=256); dev.off() a <- a$density #画像のヒストグラム表示 par(mfcol = c(1,2), mgp=c(2.5, 1, 0)) EBImage::display(ImgGr) plot(a, xlim = c(0,256), ylim=c(0, max(c(a))*1.1), xlab="Intensity value (0-255)", ylab="Density", xaxs="i", yaxs="i", type="l", col="grey50") quartz.save("Img04_Grey.png", type="png", dpi=100); dev.off()
RGB画像を各成分に分離して、各画像を表示する
R成分を取り出す場合には、GとB成分にゼロを代入して、GB成分を消去する。 GとB成分でも同じような処理をやってみる。 そして、オリジナル画像、R成分、G成分、B成分の画像を連結させて表示させる。
#RGB色の分離 Red <- Img Red[,,2] <- 0 Red[,,3] <- 0 #EBImage::display(Red) Green <- Img Green[,,1] <- 0 Green[,,3] <- 0 #EBImage::display(Green) Blue <- Img Blue[,,1] <- 0 Blue[,,2] <- 0 #EBImage::display(Blue) #RGB色で表示 EBImage::display(EBImage::combine(Img, Red, Green, Blue), nx=2, all=TRUE, spacing = 0.01, margin = 70) quartz.save("Img05_rgb.png", type="png", dpi=100); dev.off()

フィルターを変えて、画像の縮小を行い、結果を比較してみた。
EBImage::resizeとimager::resizeを使って、
様々なフィルターでの画像の縮小を試してみた。
XY軸方向に、それぞれ20%縮小した(要するに、1/25縮小)。
#縮小 + no-filter Img_n50 <- EBImage::resize(Img, w=round(dim(Img)[1]/5, 0), h=round(dim(Img)[2]/5, 0), filter="none") #縮小 + bilinear filter Img_b50 <- EBImage::resize(Img, w=round(dim(Img)[1]/5, 0), h=round(dim(Img)[2]/5, 0), filter="bilinear") #EBImageからcimgへのオブジェクト変換 img <- imageData(Img) img2 <- imager::as.cimg(img, dim=dim(img)) #警告メッセージ: # as.cimg.array(img, dim = dim(img)) で: # Assuming third dimension corresponds to colour #縮小 + no interpolation: additional space is filled according to boundary_conditions (0) Img_nnia50 <- imager::resize(img2, size_x = round(dim(img2)[1]/5, 0), size_y = round(dim(img2)[2]/5, 0), interpolation_type = 0) Img_nnia50 <- EBImage::Image(Img_nnia50[,,1,], colormode = "Color") #EBImage::display(Img_nnia50) #縮小 + nearest-neighbor interpolation (1) Img_nni50 <- imager::resize(img2, size_x = round(dim(img2)[1]/5, 0), size_y = round(dim(img2)[2]/5, 0), interpolation_type = 1) Img_nni50 <- EBImage::Image(Img_nni50[,,1,], colormode = "Color") #縮小 + moving average interpolation (2) Img_mai50 <- imager::resize(img2, size_x = round(dim(img2)[1]/5, 0), size_y = round(dim(img2)[2]/5, 0), interpolation_type = 2) Img_mai50 <- EBImage::Image(Img_mai50[,,1,], colormode = "Color") #縮小 + linear interpolation (3) Img_li50 <- imager::resize(img2, size_x = round(dim(img2)[1]/5, 0), size_y = round(dim(img2)[2]/5, 0), interpolation_type = 3) Img_li50 <- EBImage::Image(Img_li50[,,1,], colormode = "Color") #縮小 + grid interpolation (4) Img_gi50 <- imager::resize(img2, size_x = round(dim(img2)[1]/5, 0), size_y = round(dim(img2)[2]/5, 0), interpolation_type = 4) Img_gi50 <- EBImage::Image(Img_gi50[,,1,], colormode = "Color") #縮小 + cubic interpolation (5) Img_ci50 <- imager::resize(img2, size_x = round(dim(img2)[1]/5, 0), size_y = round(dim(img2)[2]/5, 0), interpolation_type = 5) Img_ci50 <- EBImage::Image(Img_ci50[,,1,], colormode = "Color") #縮小 + lanczos interpolation (6) Img_lani50 <- imager::resize(img2, size_x = round(dim(img2)[1]/5, 0), size_y = round(dim(img2)[2]/5, 0), interpolation_type = 6) Img_lani50 <- EBImage::Image(Img_lani50[,,1,], colormode = "Color") #表示 EBImage::display(EBImage::combine(Img_n50, Img_b50, Img_nnia50, Img_nni50, Img_mai50, Img_li50, Img_gi50, Img_ci50, Img_lani50), nx=3, all=TRUE, spacing = 0.01, margin = 70) m <- c(0.8, 1, 0) text(x = 100, y = 0, label = "Img_n50", adj = c(0,1), col = "white", cex = m[1], pos=m[2], srt=m[3]) text(x = 380, y = 0, label = "Img_b50", adj = c(0,1), col = "white", cex = m[1], pos=m[2], srt=m[3]) text(x = 680, y = 0, label = "Img_nnia50", adj = c(0,1), col = "white", cex = m[1], pos=m[2], srt=m[3]) text(x = 100, y = 310, label = "Img_nni50", adj = c(0,1), col = "white", cex = m[1], pos=m[2], srt=m[3]) text(x = 380, y = 310, label = "Img_mai50", adj = c(0,1), col = "white", cex = m[1], pos=m[2], srt=m[3]) text(x = 680, y = 310, label = "Img_li50", adj = c(0,1), col = "white", cex = m[1], pos=m[2], srt=m[3]) text(x = 100, y = 620, label = "Img_gi50", adj = c(0,1), col = "white", cex = m[1], pos=m[2], srt=m[3]) text(x = 380, y = 620, label = "Img_ci50", adj = c(0,1), col = "white", cex = m[1], pos=m[2], srt=m[3]) text(x = 680, y = 620, label = "Img_lani50", adj = c(0,1), col = "white", cex = m[1], pos=m[2], srt=m[3]) quartz.save("Img06_resize.png", type="png", dpi=150); dev.off()

n50、b50、nni50、gi50の縮小結果はあきらかに画像の平滑化がうまくいってなさそう。
nnia50の縮小結果は端っこしか切り取られていない。。
次に、画像(グレー変換後)のヒストグラムを図示してみる。
#レイアウト設定 par(mfrow = c(3,3), mgp=c(2.5, 1, 0), mai = c(0.5, 0.5, 0.2, 0.2)) #Img hist(array(EBImage::channel(Img, "gray"), dim=dim(Img)[1:2])*256, breaks=256, freq=F, main="Img", xlab="Intensity value (0-255)", xaxs="i", yaxs="i", ylim=c(0, 0.06)) #Img_n50 hist(array(EBImage::channel(Img_n50, "gray"), dim=dim(Img_n50)[1:2])*256, breaks=256, freq=F, main="Img_n50", xlab="Intensity value (0-255)", xaxs="i", yaxs="i", ylim=c(0, 0.06)) #Img_b50 hist(array(EBImage::channel(Img_b50, "gray"), dim=dim(Img_b50)[1:2])*256, breaks=256, freq=F, main="Img_b50", xlab="Intensity value (0-255)", xaxs="i", yaxs="i", ylim=c(0, 0.06)) #Img_nni50 hist(array(EBImage::channel(Img_nni50, "gray"), dim=dim(Img_nni50)[1:2])*256, breaks=256, freq=F, main="Img_nni50", xlab="Intensity value (0-255)", xaxs="i", yaxs="i", ylim=c(0, 0.06)) #Img_mai50 hist(array(EBImage::channel(Img_mai50, "gray"), dim=dim(Img_mai50)[1:2])*256, breaks=256, freq=F, main="Img_mai50", xlab="Intensity value (0-255)", xaxs="i", yaxs="i", ylim=c(0, 0.06)) #Img_li50 hist(array(EBImage::channel(Img_li50, "gray"), dim=dim(Img_li50)[1:2])*256, breaks=256, freq=F, main="Img_li50", xlab="Intensity value (0-255)", xaxs="i", yaxs="i", ylim=c(0, 0.06)) #Img_gi50 hist(array(EBImage::channel(Img_gi50, "gray"), dim=dim(Img_gi50)[1:2])*256, breaks=256, freq=F, main="Img_gi50", xlab="Intensity value (0-255)", xaxs="i", yaxs="i", ylim=c(0, 0.06)) #Img_ci50 hist(array(EBImage::channel(Img_ci50, "gray"), dim=dim(Img_ci50)[1:2])*256, breaks=256, freq=F, main="Img_ci50", xlab="Intensity value (0-255)", xaxs="i", yaxs="i", ylim=c(0, 0.06)) #Img_lani50 hist(array(EBImage::channel(Img_lani50, "gray"), dim=dim(Img_lani50)[1:2])*256, breaks=256, freq=F, main="Img_lani50", xlab="Intensity value (0-255)", xaxs="i", yaxs="i", ylim=c(0, 0.06)) #保存 quartz.save("Img07_histo.png", type="png", dpi=150); dev.off()
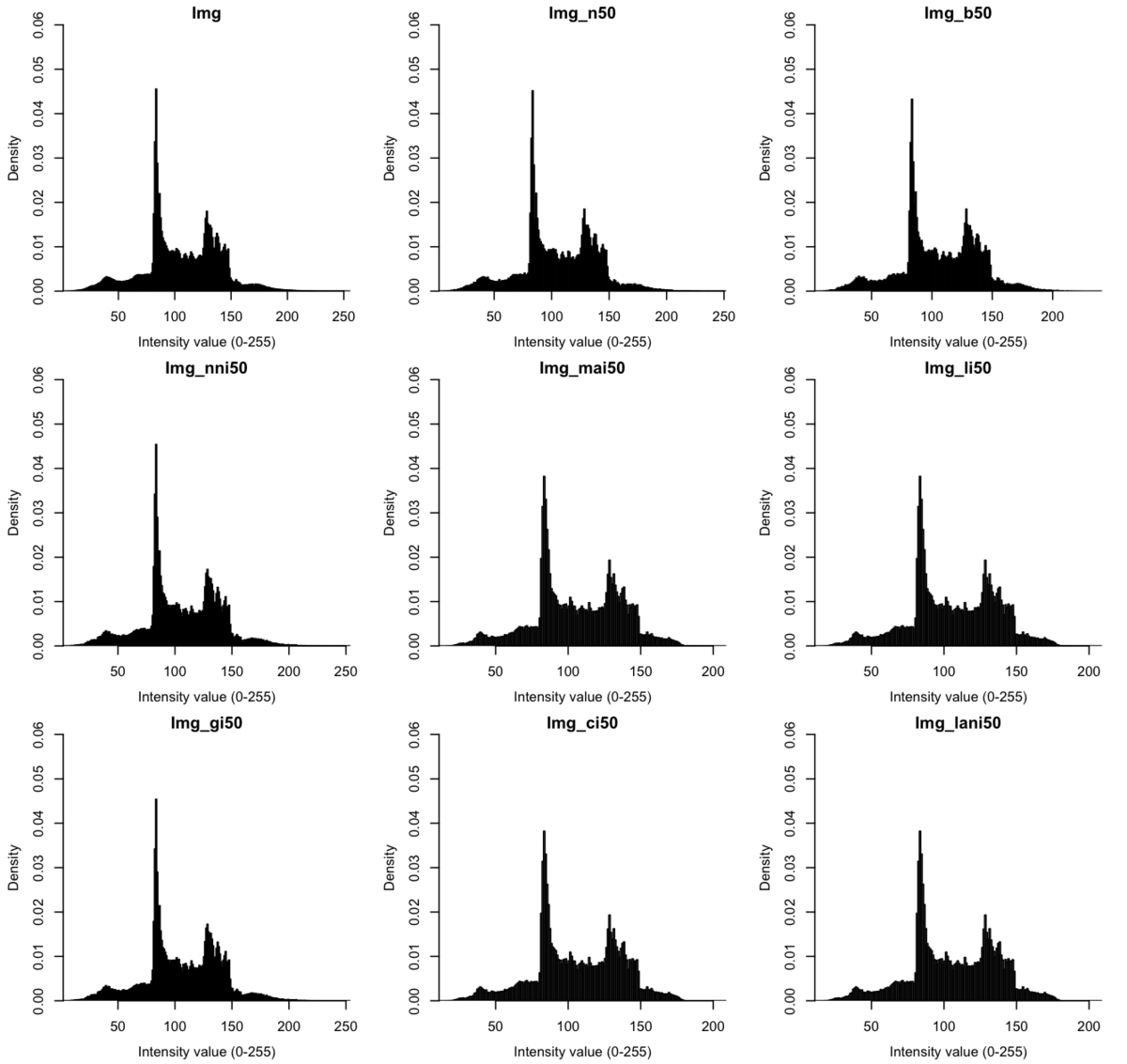
ピークの高さとか、諧調150くらいのところに少し違いがありそう。
まとめ
R/EBImage/imagerでの基本的な画像をまとめてみた。
現状、Rでの画像処理のハウツゥはほんと少ない。。
R言語でも画像処理が結構できそうなので、 少しずつスクリプトを紹介できればと思う。
参考資料
http://cse.naro.affrc.go.jp/takezawa/r-tips/r/55.htmlcse.naro.affrc.go.jp