
はじめに
twitterのつぶやきを集めて、形態素分析 + 感情分析をやってみました。
つぶやきの感情分析は、単語感情極性対応表を使って、positiveかnegativeかを評価してみた。やってみると、案外、面白かった。
まずは、Rの関連パッケージをインストールしてみます。
#インストール install.packages(c("rtweet", "devtools", "dplyr", "magrittr")) library(rtweet) library(devtools) library(dplyr) library(magrittr) #mecabのインストール system("brew install mecab mecab-ipadic") install.packages("RMeCab", repos = "http://rmecab.jp/R") library(RMeCab)
rtweetの諸設定から
はじめに、twitterアカウントの認証を行う*1。
rtweetの場合には、それが簡単で、 以下のように、とりあえず、何か実行すると、 Webブラウザが開いて、アカウント認証が求められる。
#試しに実行 search_tweets(q="つぶやき", n = 100) #Requesting token on behalf of user... #Waiting for authentication in browser... #Press Esc/Ctrl + C to abort #Authentication complete.
こんな感じで、ブラウザに認証画面が表示されます。

入力が完了すれば、Authentication completeとでます。
もし「Error in default_cached_auth():」がでた時の対処
search_tweetsを実行すると、エラーが出る場合があります。
そのときは、メッセージにしたがって、auth_setup_default()を実行します。
つぎに、Selectionで、「Yes」と入力します。
#エラーの場合 search_tweets(q="つぶやき", n = 100) #Error in `default_cached_auth()`: # ! No default authentication found. Please call `auth_setup_default()` #Run `rlang::last_error()` to see where the error occurred. #次のように実行 auth_setup_default() #ℹ The package `httpuv` is required. #✖ Would you like to install it? #1: Yes #2: No Selection: Yes
上記のように、認証画面が表示されて、、Authentication completeとなればOKです。
米国株をクエリに呟きを検索してみる。
今日の皆さんのつぶやきの感情は、ポジティブなのかネガティブなのか、、、
米国株をキーワードに、7/16未明のつぶやきを調べてみた。
#200個 検索 tweets <- search_tweets(q="米国株", n = 200) #前処理 tweetsTxt <- tweets %>% dplyr::select(text) %>% unique() #表示 head(tweetsTxt) # A tibble: 6 x 1 # text # <chr> #1 "寝る前に米国株監視。まだ眠れない…" #2 "米国株も調整入り?\nパウエル議長、テーパリング議論開始に言及\n~なんで金利は低下してい… #3 "✅米国株ライブ ヒートマップ\n指数\n ダウ -0.22% ラッセル -1.01%\n S&P500 -0.68% ナ… #4 "✅米国株ライブ ヒートマップ\n指数\n ダウ +0.08% ラッセル -0.40%\n S&P500 -0.19% ナ… #5 "✅米国株ライブ ヒートマップ\n指数\n ダウ +0.11% ラッセル -0.33%\n S&P500 -0.29% ナ… #6 "これだけ変異株があるのに、東京五輪なんて開催するなよ。\n\nイータ株、アルファ株(英国)\n…
つぶやきの形態素解析
まず試しに、1つ目のつぶやき「寝る前に米国株監視。まだ眠れない…」をRMeCabで形態素解析をしてみる。
library(RMeCab) #形態素解析 tweetsTxt1 <- unlist(tweetsTxt[1,], use.names = F) result0 <- unlist(RMeCabC(tweetsTxt1)) ##形態素解析の結果 result0 # 動詞 名詞 助詞 名詞 名詞 名詞 記号 副詞 動詞 助動詞 記号 #"寝る" "前" "に" "米国" "株" "監視" "。" "まだ" "眠れ" "ない" "…" #特定の品詞部分のみを取り出す result1 <- unique(result0[names(result0) %in% c("動詞", "名詞", "形容詞", "副詞")]) result1 #[1] "寝る" "前" "米国" "株" "監視" "まだ" "眠れ"
単語感情極性対応表を使った感情分析
感情極性とは、その語が一般的に良い印象を持つか(positive)、悪い印象を持つか(negative)を二値属性(-1から+1の実数)で表したものである*2*3。
単語感情極性対応表は、 再配布禁止のようなので、今回、Rで直接URLを読み込んでみる。
#単語感情極性対応表の読み込み(コロン区切り) pn_ja <- read.csv(file('http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic', encoding='Shift_JIS'), header = F, sep = ":") #表示 head(pn_ja) # V1 V2 V3 V4 #1 優れる すぐれる 動詞 1.000000 #2 良い よい 形容詞 0.999995 #3 喜ぶ よろこぶ 動詞 0.999979 #4 褒める ほめる 動詞 0.999979 #5 めでたい めでたい 形容詞 0.999645 #6 賢い かしこい 形容詞 0.999486 #前処理 pn_ja01 <- pn_ja$V1 pn_ja04 <- pn_ja$V4
この対応表を使って、先ほどのつぶやきの感情分析をやってみる。
#見出し語との対応をとって、二値属性の和を計算 round(sum(pn_ja04[pn_ja01 %in% result1]), 2) #[1] -2.75
値が-2.75ということで、どちらかというと、少しネガティブな呟きのようだ。
全つぶやきで、感情分析してみる。
今回、重複除去したつぶやきは全部で79個あり、それぞれで感情分析を実行してみた。
#結果を格納するデータフレーム Results <- data.frame(Sentiment=NA, Text=unlist(tweetsTxt), row.names = 1:nrow(tweetsTxt)) #つぶやき数 length(unlist(tweetsTxt)) #[1] 79 #逐次実行 for(n in 1:length(unlist(tweetsTxt))){ #n <- 1 print(n) #形態素解析 tweetsTxt1 <- unlist(tweetsTxt[n,], use.names = F) result0 <- unlist(RMeCabC(tweetsTxt1)) ##特定の品詞のみを取り出す result1 <- unique(result0[names(result0) %in% c("動詞", "名詞", "形容詞", "副詞")]) #二値属性の和 a <- pn_ja04[pn_ja01 %in% result1] result2 <- round(sum(a), 2) print("OK") #結果を格納する Results[n,1] <- result2 }
この時、match(x, table, nomatch = 0L) でエラー: 'translateCharUTF8' must be called on a CHARSXP, but got 'NULL'
とエラーがでても、再実行したらうまくいった。謎な挙動。
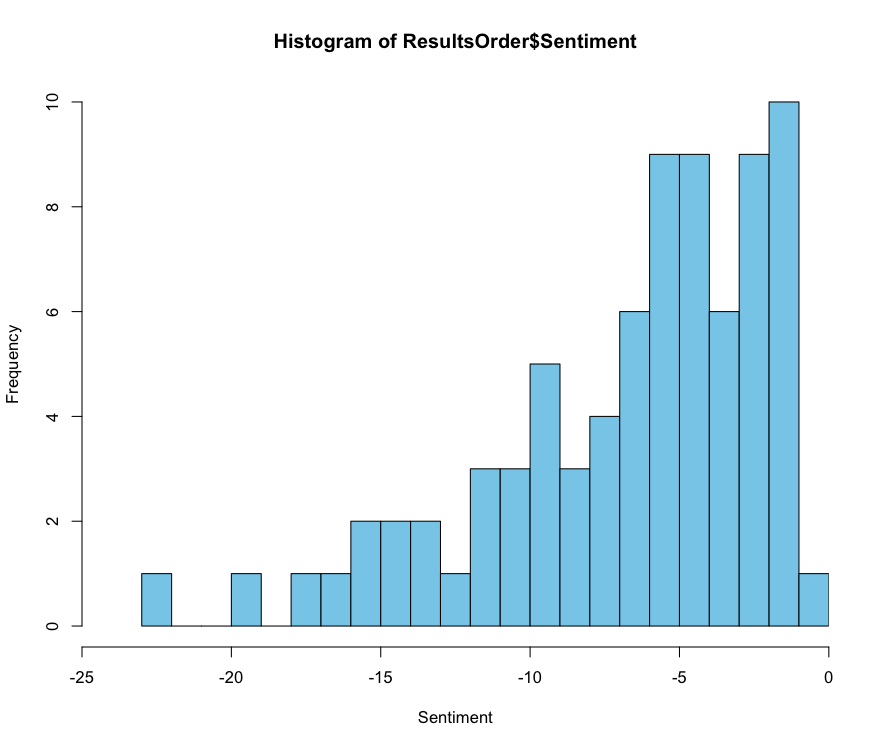
感情値で並び替えて、つぶやきとの対応を表示してみる。 また、結果をヒストグラムにしてみた。
#並び替え ResultsOrder <- dplyr::as_tibble(Results[order(Results$Sentiment, decreasing = T),]) #ポジティブ上位の表示 head(ResultsOrder, n=3) # A tibble: 3 x 2 # Sentiment Text # <dbl> <chr> #1 -0.77 "米国株、久々にめっちゃ下げてるやないかーい🤗\nって言おうと思ったけど、意外と… #2 -1.3 "【米国株セクターETF】\n⛓ $VAW 180.38 (+0.14%)\n🛒 $VCR 314.46 (-0.71%)\n☕ $V… #3 -1.3 "【米国株セクターETF】\n⛓ $VAW 181.02 (+0.50%)\n🛒 $VCR 314.89 (-0.57%)\n☕ $V… #ネガティブ上位の表示 tail(ResultsOrder, n=3) # A tibble: 3 x 2 # Sentiment Text # <dbl> <chr> #1 -17.2 "米国株のクラウドストライクですが、ちょっと頭が重い感じがするので、一度利食い… #2 -19.4 "🍀改めて自己紹介\n\n・転勤族\n・住宅ローン返済中\n・家賃収入\n・米国株長期投… #3 -22.4 "10月からは全資金の半分以上は米国株の買い付けを始める\n3ヶ月かけてゆっくり仕込… #ヒストグラム表示 hist(ResultsOrder$Sentiment, breaks=25, col = "skyblue", xlab = "Sentiment", xaxs="i", xlim = c(-25, 0)) #quartz.save(file = "./hist.png", type = "png", dpi = 100)
まとめ
呟きを分析してみると、ヒストグラムで-5付近にピークがあった。
少しネガティブ気味かもしれないけども、これくらいならまだまだ楽観と思える。
まぁ時系列で解析結果を見てみないと、何ともよく分からないんだけど。
あと、パッと思いついて、ユニークな形態素だけで、 感情属性を集計してみたけど、これはこれで良さそうに思う。
補足
M1 Macでのmecabのインストール方法 - Installation of RMeCab 1.07 on M1 Mac #13
元ネタは、このIssueを参考にしている。
M1 Macでmecabをインストールしようとすると、エラーになる。その解決法である。
まず、ターミナルを起動して、以下のコマンドを実行する。
#mecab-0.996のインストール cd ~/Downloads curl -fsSL 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE' -o mecab-0.996.tar.gz tar xf mecab-0.996.tar.gz cd mecab-0.996 ./configure --with-charset=utf8 make sudo make install #mecab-ipadic-2.7.0のインストール cd ../ curl -fsSL 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM' -o mecab-ipadic-2.7.0-20070801.tar.gz tar zvxf mecab-ipadic-2.7.0-20070801.tar.gz tar xf mecab-ipadic-2.7.0-20070801.tar.gz cd mecab-ipadic-2.7.0-20070801 ./configure --with-charset=utf-8 make sudo make install
次に、ターミナルでRを起動して、次のインストールコマンドを実行すると完了である。
#mecabのインストール install.packages("RMeCab", repos = "https://rmecab.jp/R", type = "source") library(RMeCab)
(2022年7月3日追記)
どうも、ターミナルでRを起動して、RMeCabを実行しないとうまく走らなしかも。。。
参考資料
*1:twitterのアカウント要登録
*2:高村大也, 乾孝司, 奥村学: "スピンモデルによる単語の感情極性抽出", 情報処理学会論文誌ジャーナル, Vol.47 No.02 pp. 627--637, 2006.
*3:Hiroya Takamura, Takashi Inui, Manabu Okumura: "Extracting Semantic Orientations of Words using Spin Model", In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL2005) , pages 133--140, 2005.