PyMOLは、オープンソースの分子グラフィックスツールである。
いまも、教育版(Educational-use-only PyMOL)は、以下のフォームで登録すれば、フリーで使用できるらしい。
少し前にまとめた資料であるが、PyMolコマンドのメモとしてアップしておく。
「MacPyMOL.app」を「PyMOLX11Hybrid.app」と名前を変えて、 X11 Hybrid モードで起動されることが、カッコいいと思っていたの(思い込み)が懐かしい。
PyMOLは、オープンソースの分子グラフィックスツールである。
いまも、教育版(Educational-use-only PyMOL)は、以下のフォームで登録すれば、フリーで使用できるらしい。
少し前にまとめた資料であるが、PyMolコマンドのメモとしてアップしておく。
「MacPyMOL.app」を「PyMOLX11Hybrid.app」と名前を変えて、 X11 Hybrid モードで起動されることが、カッコいいと思っていたの(思い込み)が懐かしい。

正規分布に従うデータ(乱数)を、異なるサンプルサイズで準備して、 それらデータについて、ヒストグラム・密度分布、累積分布、Q-Qプロットとかで可視化して、 アニメーションにもしてみた。
以下のアニメーションを作成した。
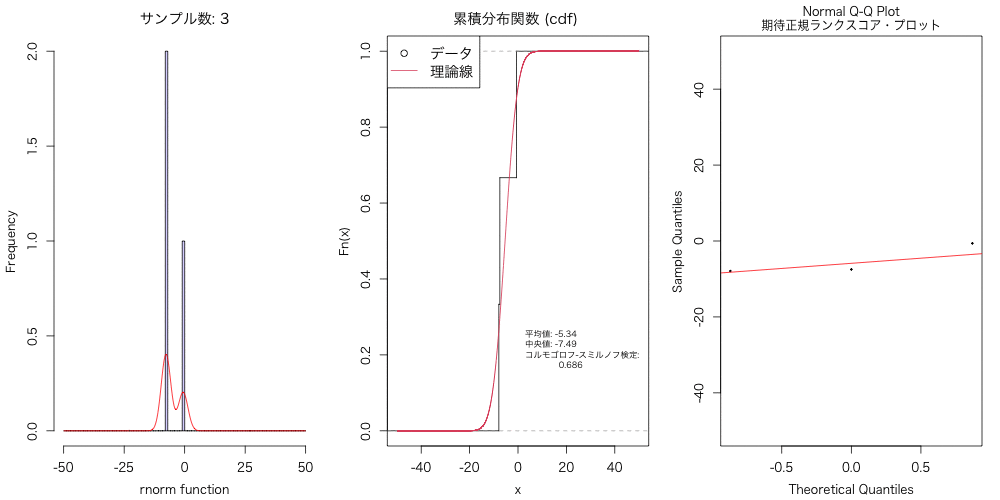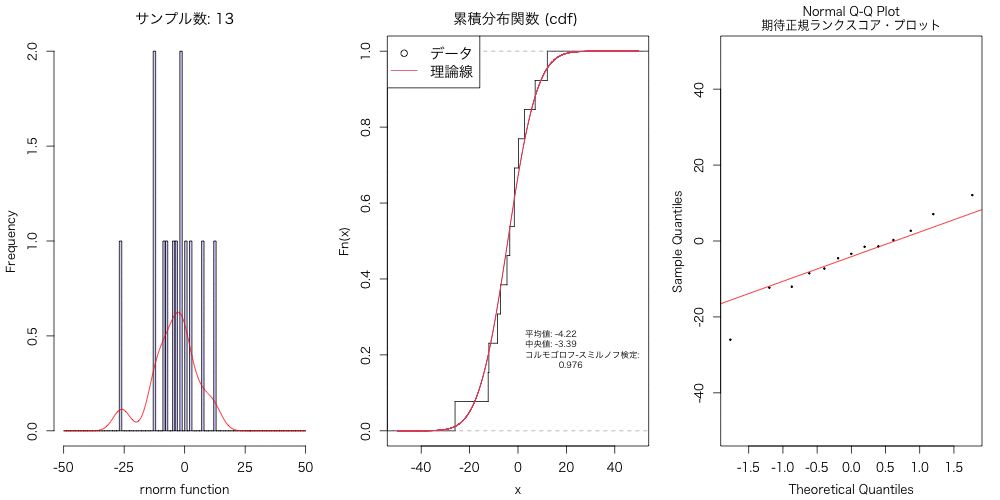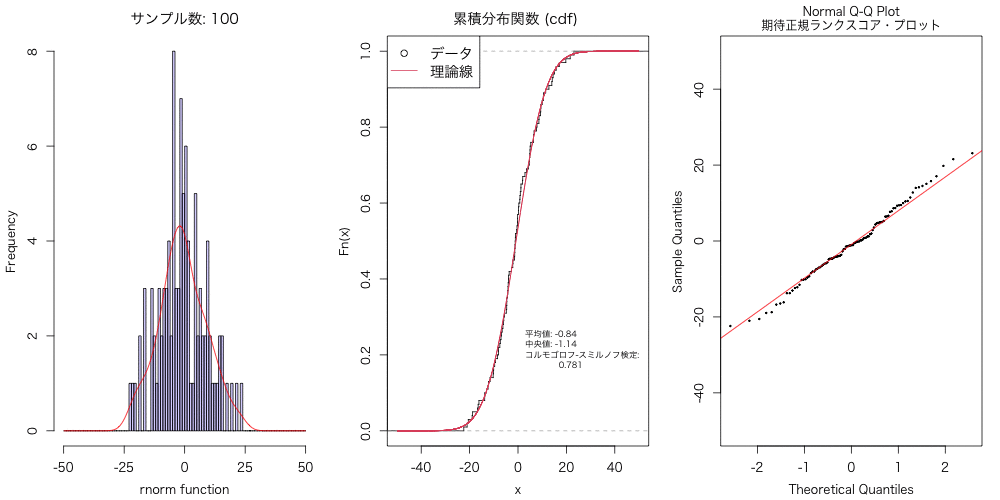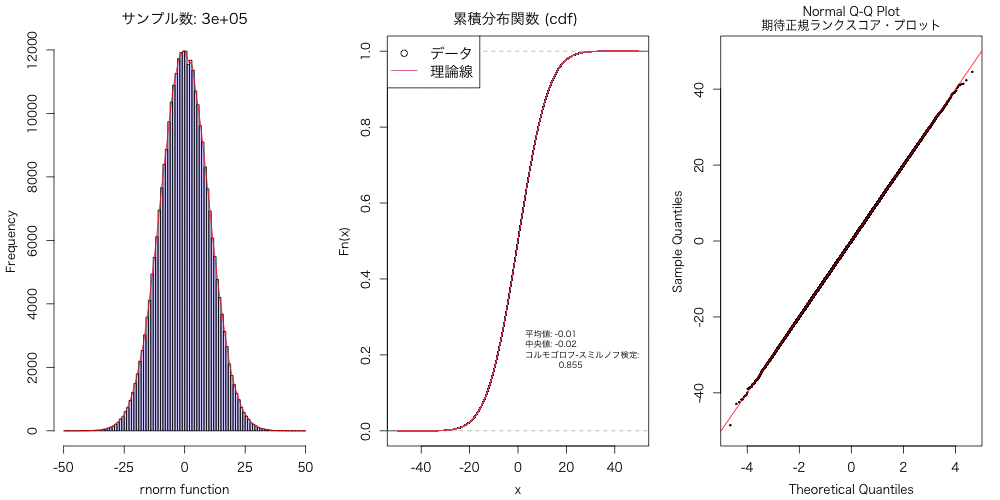
実験的に、こういうのを試すと、データ分布は数千〜数万はないと、 正規分布には近似しないよねということに気づかされる。
まずは、必要なパッケージをインストールする。
install.packages("animation") library(animation)
そして、サンプルサイズの数値を、3〜300000までの数値ベクトルにて作成する。
Num <- c(3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 17, 20, 25, 30, 40, 50, 75, 100, 300, 500, 1000, 3000, 5000, 10000, 30000, 50000, 100000, 300000)
次に、「animation::saveGIFとfor-ループ」を組み合わせて、 プロットの可視化結果をGIFアニメーションに変換する。
animation::saveGIF({ for(n in Num){ #プロット設定 par(mfrow = c(1,3), family="HiraKakuProN-W3", cex=1, mgp=c(2.5, 1, 0), mai=c(0.75, 0.75, 0.5, 0.25)) #正規分布に従う乱数を n 個生成 a <- rnorm(n, mean = 0, sd = 10) #データ分布のヒストグラム hist(a, breaks=seq(-50, 50, by=1), main=paste0("サンプル数: ", n), xlab="rnorm function", col=rainbow(10, alpha = 0.2)[8], xaxt='n') #X軸ラベルの書き直し axis(side=1, at=seq(-50, 50, 25), labels=seq(-50, 50, 25)) #密度分布 b <- density(a, kernel = "gaussian", n = 512, from=-50, to=50) lines(b$x, b$y*n, col="red") #経験的分布関数 d <- ecdf(a) plot(d, do.point=F, verticals=T, xlim=c(-50, 50), main="累積分布関数 (cdf) ") #正規分布時の理論式の追加 x <- seq(-50, 50, 0.01) lines(x, pnorm(x, mean=mean(a), sd=sqrt(var(a))), col=2) #データ分布の平均値、中央値、コルモゴロフ-スミルノフ検定 text(0, 0.2, cex=0.7, pos=4, labels=paste0("平均値: ", round(mean(a), 2), "\n", "中央値: ", round(median(a), 2), "\n", "コルモゴロフ-スミルノフ検定: \n ", round(ks.test(a, "pnorm", mean=mean(a), sd=sd(a), alternative = "two.sided")$p.value, 3))) legend("topleft", legend=c("データ", "理論線"), cex=1.2, pch=c(21, NA), lty=c(NA, 1), col=c(1, 2)) #Q-Q プロット qqnorm(a, cex=0.25, cex.main=1, ylim=c(-50,50), main="Normal Q-Q Plot\n期待正規ランクスコア・プロット") qqline(a, col="red") }}, movie.name = paste0("Animation.gif"), interval = 1, dpi=400, nmax = length(Num), ani.width = 1000, ani.height=500, ani.type="png")
F(x) = P(X ≤ x) (値が、 x 以下になる確率)
これに従う関数を、累積分布関数という。
主に、サンプル数が多めで、30以上の場合に使用する検定である。
この検定の帰無仮説は「二つの分布が等しい」となるので、正規分布(pnorm関数)との比較では棄却されないほうが望ましい。
要するに、p > 0.05の時には、有意水準が5%で帰無仮説は棄却されず、データの分布は有意に正規分布に従うこととなる。
qqline「データの上四分位点と下四分位点を結ぶ直線」上に、データ点がプロットされる場合、データが正規分布していると判断される。

「シングルバイト文字」は、1バイト(7ビット、または8ビット)のデータ量で表現できる文字である。文字コードとしては、ASCIIコードなどが該当する。
一方、ダブルバイト文字は、1文字を2バイト以上(16ビット以上)のデータ量で表現できる文字である。JISコード、Shift JISコードなどがそれに該当する。
以下、簡単な表にまとめてみた。
| 文字の種類 | 説明 | 文字コードの例 |
|---|---|---|
| シングルバイト文字*1 | 1バイト(7ビットまたは8ビット)のデータ量で表現できる文字 | 主にアルファベットや数字 ASCIIコード、ISO/IEC 8859 など |
| ダブルバイト文字 *2 | 1文字を2バイト以上のデータ量で表現できる文字 | JIS X 0208、JISコード、Shift JISコード、EUC-JP、など |
UTF-8 *3やUTF-16 *4は、Unicode / UCS *5で定義された文字集合で表現できる文字コードである。
Unicodeには、「BOM無し」と「BOM付き」の2種類のファイルが存在する。 BOMは、「バイトオーダーマーク(Byte Order Mark)」の略で、 Unicodeで符号化したテキストの先頭に付与される数バイトのデータのことを指す。 具体的には、バイナリの先頭に付く、<0xEF 0xBB 0xBF> が BOM である。
実際、UTF-8のファイルにはBOMは必要ないものであるが、 「Excel」「メモ帳」など Microsoft のアプリ、Macのアプリでは、 「BOM」を付けないと、日本語文字がうまく読めず、文字化けを起こすことがある。
「\uXXXX」といったUnicodeエスケープ文字、「%XX」といったURLエンコード(パーセントエンコード)文字というのがある。
Unicodeエスケープ形式の文字では、「\u」に文字の符号位置を表す16進数の値を付加することで、1文字を 「\uXXXX」 のような16進数4桁のコード形式にて表す。
また、パーセント・エンコード形式の文字では、「%」に16進数の値を付加することで、1文字を「%XX」のような16進数2桁のコード形式にて表す。
日本語などの文字列は、URLとしてそのまま扱うことができないため、エンコード形式の文字を使用する。URLとして使う際に、「%」付きの半角英数字・記号に変換することから、「URLエンコード」と呼ばれる。逆に、元の文字列に戻すことを「URLデコード」という。
nkfは、ものすごく古い漢字コード変換プログラムである*6。
まず、Homebrewで、nkfコマンドをインストールする。
ターミナルを起動して、以下を実行する。
#nkf コマンドのインストール brew install nkf #バージョン確認 nkf --version #Network Kanji Filter Version 2.1.5 (2018-12-15) #Copyright (C) 1987, FUJITSU LTD. (I.Ichikawa). #Copyright (C) 1996-2018, The nkf Project. #【nkfコマンドの主なオプション】 #-u: 出力時にバッファリングを行わない #-j: JISコードに変換する #-e: EUCコードに変換する #-s: Shift JISコードに変換する #-w: UTF8コードに変換する #-r: ROT13/47の変換する #-T: テキスト・モードで出力する #file: 変換元のファイルを指定する #-g: 文字コード自動判別の結果を表示 #–overwrite: 引数のファイルに直接上書き
テスト・ファイルをダウンロードする。
wget https://raw.githubusercontent.com/kumeS/Blog/master/nkf_test/test.txt
ファイルの文字コードを表示
nkf -g test.txt #UTF-8
Shift JISコードに変換する。
nkf -s test.txt > test01.txt #ファイルの文字コードを表示 nkf -g test01.txt #Shift_JIS #上書きの場合 #nkf -s --overwrite test.txt
UTF8コードに変換する。
nkf -w test01.txt > test02.txt #ファイルの文字コードを表示 nkf -g test02.txt #UTF-8 #上書きの場合 #nkf -w --overwrite test01.txt
#nkfで、BOM付きに変換 nkf --oc=UTF-8-BOM test.txt > test_BOM.txt #上書きの場合 #nkf --overwrite --oc=UTF-8-BOM test.txt #OR #テキストの先頭にBOM文字列を、catで追記する #cat <(printf "\xEF\xBB\xBF") BOM無しファイル.txt > BOM付きファイル.txt #ダブルクォーテーションは半角で、、 cat <(printf "\xEF\xBB\xBF") test02.txt > test02_BOM.txt
見た目では分からないが、エクセルとかで開いてみると違いがわかる。
別のテスト・ファイルをダウンロードする。
wget https://raw.githubusercontent.com/kumeS/Blog/master/nkf_test/nkf_test.txt #例題 cat nkf_test.txt #\u30D9\u30EB\u30AE\u30FC #\u5E78\u798F #\u30B8\u30E7\u30FC\u30B8\u30FB\u30EF\u30B7\u30F3\u30C8\u30F3 #\u30B8\u30E3\u30C3\u30AF\u30FB\u30D0\u30A6\u30A2\u30FC #\u30A6\u30A3\u30AD\u30C7\u30FC\u30BF #\u5357\u6975\u5927\u9678 #\u30B3\u30F3\u30D4\u30E5\u30FC\u30BF
それでは、Unicodeエスケープシーケンス形式の文字を日本語文字に変換してみる。
# エスケープ文字を日本語に変換する(デコード) cat nkf_test.txt | sed 's/\\\u\(....\)/\&#x\1;/g' | nkf --numchar-input -w > nkf_test2.txt #変換結果を表示 cat nkf_test2.txt #ベルギー #幸福 #ジョージ・ワシントン #ジャック・バウアー #ウィキデータ #南極大陸 #コンピュータ #エンコードについては、改行の入れ方を少し検討中 #cat nkf_test2.txt | iconv -t UCS-2 | xxd -p | fold -w4 | xargs -n1 printf '\\u%s' > nkf_test2_encode.txt #cat nkf_test2_encode.txt #\u30d9\u30eb\u30ae\u30fc\u000a\u5e78\u798f\u000a\u30b8\u30e7\u30fc\u30b8\u30fb\u30ef\u30b7\u30f3\u30c8\u30f3\u000a\u30b8\u30e3\u30c3\u30af\u30fb\u30d0\u30a6\u30a2\u30fc\u000a\u30a6\u30a3\u30ad\u30c7\u30fc\u30bf\u000a\u5357\u6975\u5927\u9678\u000a\u30b3\u30f3\u30d4\u30e5\u30fc\u30bf\u000a
パーセント・エンコード文字を日本語文字に変換してみる。
#パーセント・エンコード: 日本語 => パーセント文字 cat nkf_test2.txt | nkf -WwMQ | tr = % > nkf_test3.txt #変換結果を表示 cat nkf_test3.txt #%E3%83%99%E3%83%AB%E3%82%AE%E3%83%BC #%E5%B9%B8%E7%A6%8F #%E3%82%B8%E3%83%A7%E3%83%BC%E3%82%B8%E3%83%BB%E3%83%AF%E3%82%B7%E3%83%B3% #%E3%83%88%E3%83%B3 #%E3%82%B8%E3%83%A3%E3%83%83%E3%82%AF%E3%83%BB%E3%83%90%E3%82%A6%E3%82%A2% #%E3%83%BC #%E3%82%A6%E3%82%A3%E3%82%AD%E3%83%87%E3%83%BC%E3%82%BF #%E5%8D%97%E6%A5%B5%E5%A4%A7%E9%99%B8 #%E3%82%B3%E3%83%B3%E3%83%94%E3%83%A5%E3%83%BC%E3%82%BF #URLデコード: パーセント文字 => 日本語 cat nkf_test3.txt | nkf -w --url-input > nkf_test4.txt #変換結果を表示 cat nkf_test4.txt #ベルギー #幸福 #ジョージ・ワシン% #トン #ジャック・バウア% #ー #ウィキデータ #南極大陸 #コンピュータ #どうも、「%」が残っている、、変換に失敗しているっぽい。 #こっちが正解っぽい。 cat nkf_test3.txt | tr % = | nkf -WwmQ > nkf_test5.txt #変換結果を表示 cat nkf_test5.txt #ベルギー #幸福 #ジョージ・ワシントン #ジャック・バウアー #ウィキデータ #南極大陸 #コンピュータ
どうも、nkfコマンドは、出力文字列が76文字を超えると、勝手に改行が挿入されるらしい。
76文字を超える文字列では、nkf -w --url-inputではうまく変換できない。
そういう場合には、tr % = | nkf -WwmQを使うと良い。
「文字コード変換」という悩ましい問題をまとめてみた。
ファイル数が1つあるいは少ない場合には、 例えば、「BOM付きにする」とかの簡単な変換であれば、 CotEditor などのテキストエディターを使って、 エンコードを変更するのが手っ取り早い。
Windows OSは、MS-DOS(Microsoft Disk Operating System)というCUIのOSが起源と言われます。 当初、GUIの画面表示で操作できませんでした。
Mac OSは、BSD系Unixをベースに開発されました。Mac OSは初期の頃からマウス操作が主体のGUIが実装されていました。また、Unix(公式な商標は「UNIX」)は1969年にAT&Tのベル研究所にて開発を開始され、現代的なOSの始祖といわれるOSです。
Linuxは、1991年にヘルシンキ大学の学生であった、リーナス・トーバルズによって開発されました。 Linuxは、Unixを参考にゼロから作られたと言われています。そのため、Unixとよく似ています。 Linuxがオープンソースソフトウエアとして広く公開されており、 誰でも入手し、改変などが可能なライセンスで使用が許可されています。
http://feynmanino.watson.jp/2737_nkf.htmlfeynmanino.watson.jp