
はじめに
SPARQL(スパークル)は、RDF(Resource Description Framework)問合せ言語の1つである。SPARQL言語、SPARQLクエリとも呼ばれる。
主に、RDF形式のLinked Data / ナレッジグラフ、またはオープンなライセンスで公開されているOpen Linked Data (LOD)、*1の検索に用いられる。
今回、curlコマンドを使って、Wikidata*2や大阪市Linked Open DataといったLODに対して、SPARQLクエリでの検索を試みる。
今回扱う、curlコマンドは、URLシンタックスを用いて、ファイル・テキストを送信・受信するコマンドラインツールである*3。基本的な使い方としては、HTTPリクエストを送って、その結果受け取った内容を出力する。
SPARQLクエリの詳細な仕様が知りたい場合には、以下の日本語サイトが有用である。
curl コマンドを用いたSPARQL実行の基本形
curl -H [出力データ形式] --data-urlencode 'query=[SPARQLクエリ]' [SPARQLエンドポイントのURL]
大事なこととして、SPARQLクエリは、'query=[SPARQLクエリ]'のところ*4に記述する。
-Hオプションで、HTTPヘッダにHEADERを追加・変更する。ここには、出力データ形式を記述する。出力したいデータ形式にあわせて変更する。
| データ形式 | 引数 |
|---|---|
| csv (コンマ区切り) | 'Accept: text/csv' |
| tsv (タブ区切り) | 'Accept: text/tab-separated-values' |
| json形式 | 'Accept: application/sparql-results+json' |
| xml形式 | 'Accept: application/sparql-results+xml' |
SPARQLエンドポイントのURLには、クエリの問い合わせ先のURL、つまりは、RDF形式のデータベースの所在URLを指定する。今回、以下のエンドポイントのURLを用いる。
| SPARQLエンドポイント | URL |
|---|---|
| Wikidata 公式版 | https://query.wikidata.org/sparql |
| 大阪市LOD | https://data.city.osaka.lg.jp/sparql |
実施例①-1: WikidataでのSPRQLクエリ 〜データサイエンスの下位概念〜
SPARQLクエリの作成において、主に、Select節とWhere節を記述することになる。
Select節には、?から始まる出力したい変数名(Ex. ?s)を記述する。複数変数の場合には、スペースで区切る。
Where節には、検索したいトリプル(主語 - 述語 - 目的語の組み合わせ)の関係を記述する。また、1文ごとに. (ピリオド)で締めくくり、複数の条件で検索することができる。
例題として、「データサイエンスを上位クラスとする下位エンティティ(?s)を検索するクエリ」を取り上げる。wd:Q2374463はwikidata内での「データサイエンスのエンティティ」を、wdt:P279はwikidata内での「上位クラスのプロパティ」を指し示す。ここで、wd:はhttp://www.wikidata.org/entity/、wdt:はhttp://www.wikidata.org/prop/direct/のURI省略形である。
select ?s ?sLabel
where {
?s wdt:P279 wd:Q2374463 .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en" }
}
ここで、SERVICE wikibase:label { bd:serviceParam wikibase:language "en" }はWikidata独自のAPIであり、
この行を追加することで、?sLabel とするだけで、?sに対応する英語などのラベル情報が出力される。
以下、Wikidataのクエリサービスで実行した結果である。

同じクエリを、curlコマンドで書いて、ターミナルで実行する場合は、以下となる。
$ curl -H 'Accept: text/csv' --data-urlencode 'query=select ?s ?sLabel where { ?s wdt:P279 wd:Q2374463 . SERVICE wikibase:label { bd:serviceParam wikibase:language "en" } }' https://query.wikidata.org/sparql > test.txt # % Total % Received % Xferd Average Speed Time Time Time Current # Dload Upload Total Spent Left Speed #100 373 100 188 100 185 161 159 0:00:01 0:00:01 --:--:-- 320 $ cat test.txt #s,sLabel #http://www.wikidata.org/entity/Q45933174,data ethics #http://www.wikidata.org/entity/Q58483256,data tribology #http://www.wikidata.org/entity/Q80393317,responsible data science
実際、コマンドで実行すると、やや冗長となってしまう。そのため、バッチファイル.commnadを作成して実行するのが良いように思う。
以下に、.commnadファイルでの実行例を解説する。
サンプルクエリは、GitHubリポジトリにアップロードしている。(Macであれば)そのバッチファイルをダウンロードして、ファイルをダブルクリックすれば実行できる*5。
svnコマンドで、GitHubからダウンロードするコマンドは、以下の通りである。*6
brew install svn
svn export https://github.com/kumeS/Blog/trunk/sparql_curl_samples
実施例①-2: WikidataでのSPRQLクエリ 〜データサイエンスの上位概念〜
次に、データサイエンス(wd:Q2374463)の上位クラスあるいはインスタンス関係にある目的語を取得するクエリを説明する。
ここでは、プロパティ関係を明示的に出力するために、wikibase:directClaimなどを使ってプロパティのラベル名を取得している。
また、csv、tsv、jasonなどの形式で出力している。
SPARQL_Example01.command
#!/bin/bash MY_DIRNAME=$(dirname $0) cd $MY_DIRNAME QUERY='query=select ?o ?oLabel ?prop ?propLabel where { wd:Q2374463 wdt:P31|wdt:P279 ?o ; ?p ?o . ?prop wikibase:directClaim ?p . SERVICE wikibase:label { bd:serviceParam wikibase:language "ja" } }' #csv出力 Output='Accept: text/csv' Endpoint='https://query.wikidata.org/sparql' curl -H "$Output" --data-urlencode "$QUERY" $Endpoint > test_01A.txt #tsv出力 Output='Accept: text/tab-separated-values' curl -H "$Output" --data-urlencode "$QUERY" $Endpoint > test_01B.txt #json出力 Output='Accept: application/sparql-results+json' curl -H "$Output" --data-urlencode "$QUERY" $Endpoint > test_01C.txt #xml出力 Output='Accept: application/sparql-results+xml' curl -H "$Output" --data-urlencode "$QUERY" $Endpoint > test_01D.txt exit
結果出力(一部)

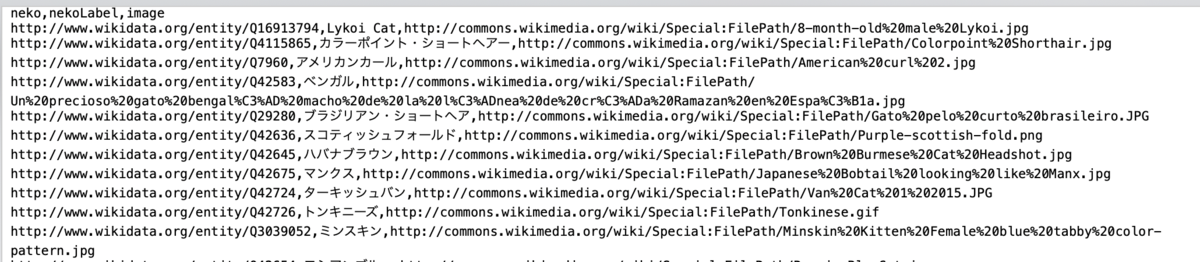
実施例②: WikidataでのSPRQLクエリ 〜猫種の検索・画像URL〜
次のクエリは、猫種のラベルを持つ主語エンティティを検索して、その下位概念のエンティティ(各々の猫エンティティ)で画像URL(wdt:P18)を持つ猫種のみの結果を出力するクエリである。
SPARQL_Example02.command
#!/bin/bash MY_DIRNAME=$(dirname $0) cd $MY_DIRNAME item='"猫種"@ja' QUERY='query=select distinct ?neko ?nekoLabel ?image where { ?s rdfs:label '$item' . ?neko wdt:P31|wdt:P279 ?s . ?neko wdt:P18 ?image . SERVICE wikibase:label { bd:serviceParam wikibase:language "ja,en" } }' Output='Accept: text/csv' Endpoint='https://query.wikidata.org/sparql' curl -H "$Output" --data-urlencode "$QUERY" $Endpoint > test_02.txt exit
結果出力(一部)
実施例③: 大阪市LODでのSPRQLクエリ 〜いろいろ〜 *7
次のバッチファイルでは、3つのクエリを実行している。クエリ①では、「都島区」を含む施設名を検索している。クエリ②では、「都島区」を含むイベント名を検索している。クエリ③では、警察・交番の名前、区名、地理情報を検索している。
SPARQL_Example03.command
#!/bin/bash MY_DIRNAME=$(dirname $0) cd $MY_DIRNAME #クエリ① QUERY='query= PREFIX ic: <http://imi.ipa.go.jp/ns/core/rdf#> PREFIX dsv: <http://datashelf.jp/ns/dsv#> select distinct ?s ?o where { ?s ?p ic:施設型 . ?s rdfs:label ?o . FILTER regex (?o, "都島区", "i") }' Output='Accept: text/csv' Endpoint='https://data.city.osaka.lg.jp/sparql' curl -H "$Output" --data-urlencode "$QUERY" $Endpoint > test_03A.txt #クエリ② QUERY='query= PREFIX ic: <http://imi.ipa.go.jp/ns/core/rdf#> PREFIX dsv: <http://datashelf.jp/ns/dsv#> select distinct ?s ?o where { ?s ?p ic:イベント型 . ?s rdfs:label ?o . FILTER regex (?o, "都島区", "i") }' Output='Accept: text/csv' Endpoint='https://data.city.osaka.lg.jp/sparql' curl -H "$Output" --data-urlencode "$QUERY" $Endpoint > test_03B.txt #クエリ③ QUERY='query= PREFIX ic: <http://imi.ipa.go.jp/ns/core/rdf#> PREFIX dsv: <http://datashelf.jp/ns/dsv#> select distinct ?s ?sLabel ?o1 ?o2 ?o3 where { ?s ?p ic:施設型 . ?s rdfs:label ?sLabel . ?s ic:種別 "警察・消防/警察・交番" . ?s ic:住所 / ic:区 ?o1 . ?s ic:地理座標 / ic:緯度 ?o2 . ?s ic:地理座標 / ic:経度 ?o3 . }' Output='Accept: text/csv' Endpoint='https://data.city.osaka.lg.jp/sparql' curl -H "$Output" --data-urlencode "$QUERY" $Endpoint > test_03C.txt exit
クエリ①の結果出力

クエリ②の結果出力

クエリ③の結果出力

まとめ
すぐにSPARQLクエリを試したい場合とかは、curlで実行すると、ライブラリをインストールしたりの環境構築の面倒がないのがよいのかも。
困りごととしては、シングルクォーテーション(')、ダブルクォーテーション(")の使い方が結構ハマる。。
次回以降で、Rでの実行についても解説する予定である。
参考資料
https://data.city.osaka.lg.jp/api/data.city.osaka.lg.jp
*1:つまりは、Web上のSPARQLエンドポイント向け
*2:通常の理解としては、「Wikipediaのデータ版」である。ただ、必ずしも、Wikipediaとは対応しておらず、Wikidata独自に構築されている部分もある。
*3:https://ja.wikipedia.org/wiki/CURL
*4: = の周辺に変なスペースとかを付けると、よくエラーとなる
*5:事前に、chmod +x SPARQL_Example01.command などと、ファイルに実行権限を与える必要があるかも
*6:「svn: error: The subversion command line tools are no longer provided by Xcode.」と最近、Xcodeでのsvnのサポートが終わったようで、brewでsvnをインストールする必要がある
*7:大阪市LODのデータは、最近更新されていないっぽい。。。