#入力文字列
Sentence <-"Hello, world"#curlを用いて、DeepL API実行
a <-system(paste0('curl -s https://api-free.deepl.com/v2/translate -d "auth_key=[Your Authentication Key]" -d "text=', Sentence,'" -d source_lang="EN" -d "target_lang=JA"'), intern =T)#前処理
result <-strsplit(strsplit(as.character(a),"\"text\":\"")[[1]][2],"\"}]}")[[1]][1]#出力結果
result
#[1] "ハロー、ワールド"
DeepLの練習(2)専門的な文書の翻訳: 日本語 to 英語
source_langを"JA"、target_langを"EN"と設定します。
[Your Authentication Key]に承認キーを入力します、また、[ ]は不要です。
#入力文字列
Sentence <-"薬品とは、精製あるいは配合されて、何らかの用途に利用可能な状態とした化学物質のうち、少量で使用するものをいう。"#curlを用いて、DeepL API実行
a <-system(paste0('curl -s https://api-free.deepl.com/v2/translate -d "auth_key=[Your Authentication Key]" -d "text=', Sentence,'" -d source_lang="JA" -d "target_lang=EN"'), intern =T)#前処理
result <-strsplit(strsplit(as.character(a),"\"text\":\"")[[1]][2],"\"}]}")[[1]][1]#結果
result
#[1] "A chemical is a chemical substance that has been refined or blended to make it usable for some purpose, and that is used in small quantities."
# HGEN 473 - Genomics
# Spring 2017
# Tuesday, May 9 & Thursday, May 11
# RNA-seq analysis with R/Bioconductor
# John Blischak
# Last updated: 2020-04-08
# https://gist.github.com/jdblischak/fdb1745612927252a7633751e5e60bcb
今回使用するRコードは、Charity Law et al.の論文「RNA-seq analysis is easy as 1-2-3 with limma, Glimma and edgeR」(2017年)から引用している。原書論文、及びその派生作品は、CC-BY4.0ライセンスで自由に利用できる。
# 原著: https://f1000research.com/articles/5-1408/v2
# ソースコード: https://bioconductor.org/packages/release/workflows/html/RNAseq123.html
# 引用: Law CW, Alhamdoosh M, Su S et al. RNA-seq analysis is easy as 1-2-3
# with limma, Glimma and edgeR [version 2; referees: 3 approved].
# F1000Research 2016, 5:1408 (doi: 10.12688/f1000research.9005.2)
install.packages("BiocManager")
BiocManager::install("RNAseq123")#Update all/some/none? [a/s/n]: #と聞かれたら a を入力して、Enter#Do you want to install from sources the packages which need compilation? (Yes/no/cancel)#と聞かれたら Yes を入力して、Enterinstall.packages("Matrix")#Do you want to install from sources the package which needs compilation? (Yes/no/cancel) no#>> #と聞かれたら no を入力して、Enter#ワークフローパッケージ「RNAseq123」を読み込むlibrary(RNAseq123)
# データセットの引用:
# Sheridan JM, Ritchie ME, Best SA, et al.: A pooled shRNA screen for
# regulators of primary mammary stem and progenitor cells identifies
# roles for Asap1 and Prox1. BMC Cancer. 2015; 15(1): 221.
# The limma User's Guide (run `limmaUsersGuide()` in the R console) is
# very useful. Especially see Section 2.1 for citations to the primary
# publications that describe the methods and Chapter 9 for how to
# contruct the model for different types of study designs.
# The Bioconductor support site (https://support.bioconductor.org/)
# has years worth of questions and answers about RNA-seq analysis and
# other topics in bioinformatics.
# Overview of RNA-seq analysis
#
# A. Oshlack, M. D. Robinson and M. D. Young. “From RNA-seq reads to
# differential expression results”. In: _Genome Biology_ 11.12 (2010),
# p. 220. DOI: 10.1186/gb-2010-11-12-220.
# R/Bioconductor tutorial starting from fastq files
#
# Chen Y, Lun ATL and Smyth GK. From reads to genes to pathways:
# differential expression analysis of RNA-Seq experiments using
# Rsubread and the edgeR quasi-likelihood pipeline [version 2;
# referees: 5 approved]. F1000Research 2016, 5:1438 (doi:
# 10.12688/f1000research.8987.2)
# Comparisons of RNA-seq methods for differential expression testing
#
# F. Rapaport, R. Khanin, Y. Liang, et al. “Comprehensive evaluation
# of differential gene expression analysis methods for RNA-seq data”.
# In: _Genome Biology_ 14.9 (2013), p. R95. DOI:
# 10.1186/gb-2013-14-9-r95.
#
# C. Soneson and M. Delorenzi. “A comparison of methods for
# differential expression analysis of RNA-seq data”. In: _BMC
# Bioinformatics_ 14.1 (2013), p. 91. DOI: 10.1186/1471-2105-14-91.
# limma
#
# Ritchie ME, Phipson B, Wu D, et al.: limma powers differential
# expression analyses for RNA-sequencing and microarray studies.
# Nucleic Acids Res. 2015; 43(7): e47.
# Glimma
#
# Su S, Ritchie ME: Glimma: Interactive HTML graphics for RNA-seq
# data. 2016; R package version 1.1.1.
# edgeR
#
# Robinson MD, McCarthy DJ, Smyth GK: edgeR: a Bioconductor package
# for differential expression analysis of digital gene expression
# data. Bioinformatics. 2010; 26(1): 139–140.
# Bioconductor project
#
# Huber W, Carey VJ, Gentleman R, et al.: Orchestrating
# high-throughput genomic analysis with Bioconductor. Nat Methods.
# 2015; 12(2): 115–121.
# TMM normalization
#
# Robinson MD, Oshlack A: A scaling normalization method for
# differential expression analysis of RNA-seq data. Genome Biol. 2010;
# 11(3): R25.
# limma+voom
#
# Law CW, Chen Y, Shi W, et al.: voom: Precision weights unlock linear
# model analysis tools for RNA-seq read counts. Genome Biol. 2014;
# 15(2): R29
# Empirical Bayes to estimate gene expression variance
#
# Smyth GK: Linear models and empirical bayes methods for assessing
# differential expression in microarray experiments. Stat Appl Genet
# Mol Biol. 2004; 3(1): Article3.
#データ準備
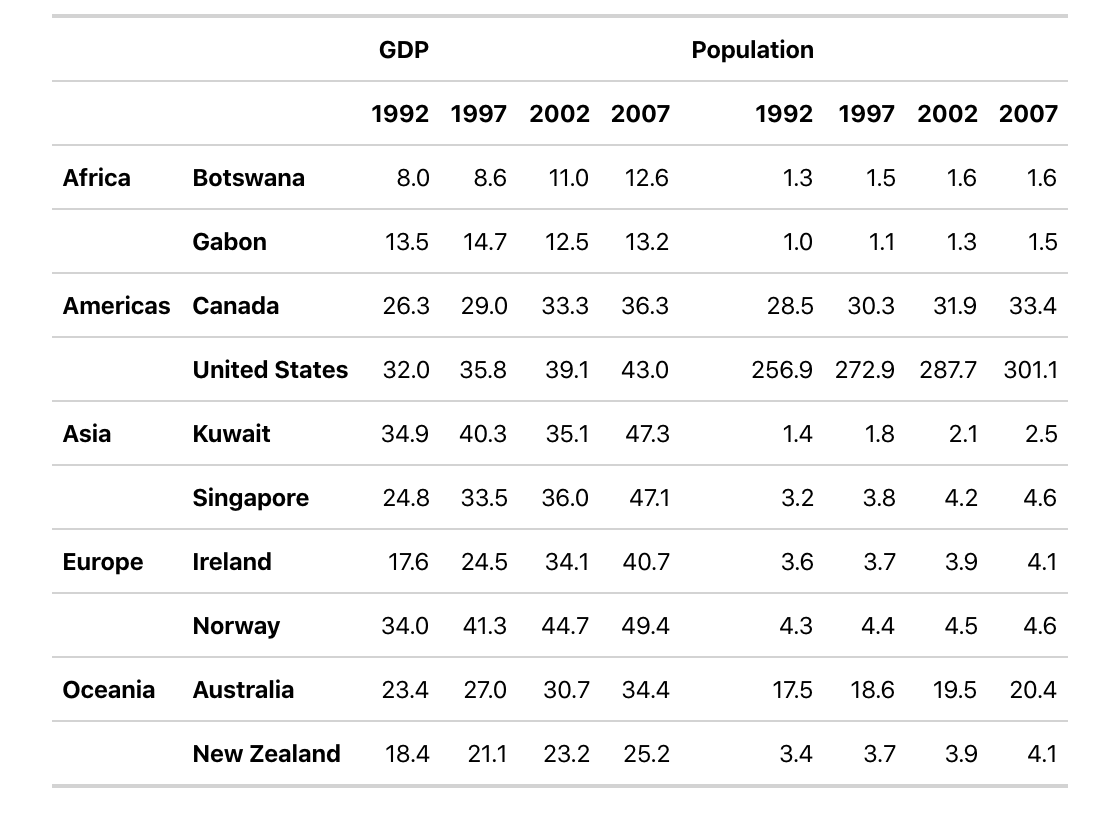
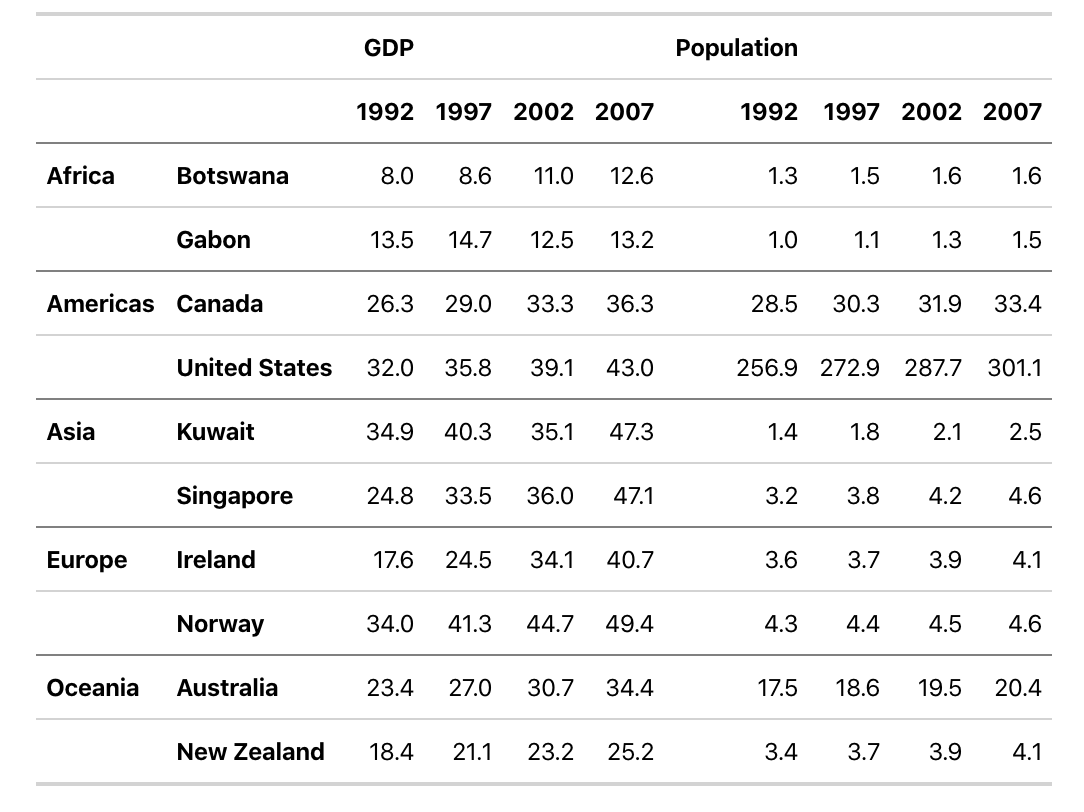
gm_df <- gapminder_mm %>%filter(var !="Life expectancy")head(gm_df)# A tibble: 6 x 5# country continent year var value# <chr> <fct> <int> <chr> <chr>#1 Australia Oceania 1992 Population 17.5 #2 Australia Oceania 1997 Population 18.6 #3 Australia Oceania 2002 Population 19.5 #4 Australia Oceania 2007 Population 20.4 #5 Botswana Africa 1992 Population 1.3 #6 Botswana Africa 1997 Population 1.5
table_gm <- gm_df %>%mmtable(table_data = value)+header_top(year)+header_top_left(var)+header_left(country)+header_left_top(continent)
table_gm