
はじめに
Rを用いた、核酸配列データの基本的な処理の方法をメモっておく。
今回は、seqinrパッケージを使って、DNA配列データの処理を行う。
DNAの基礎知識
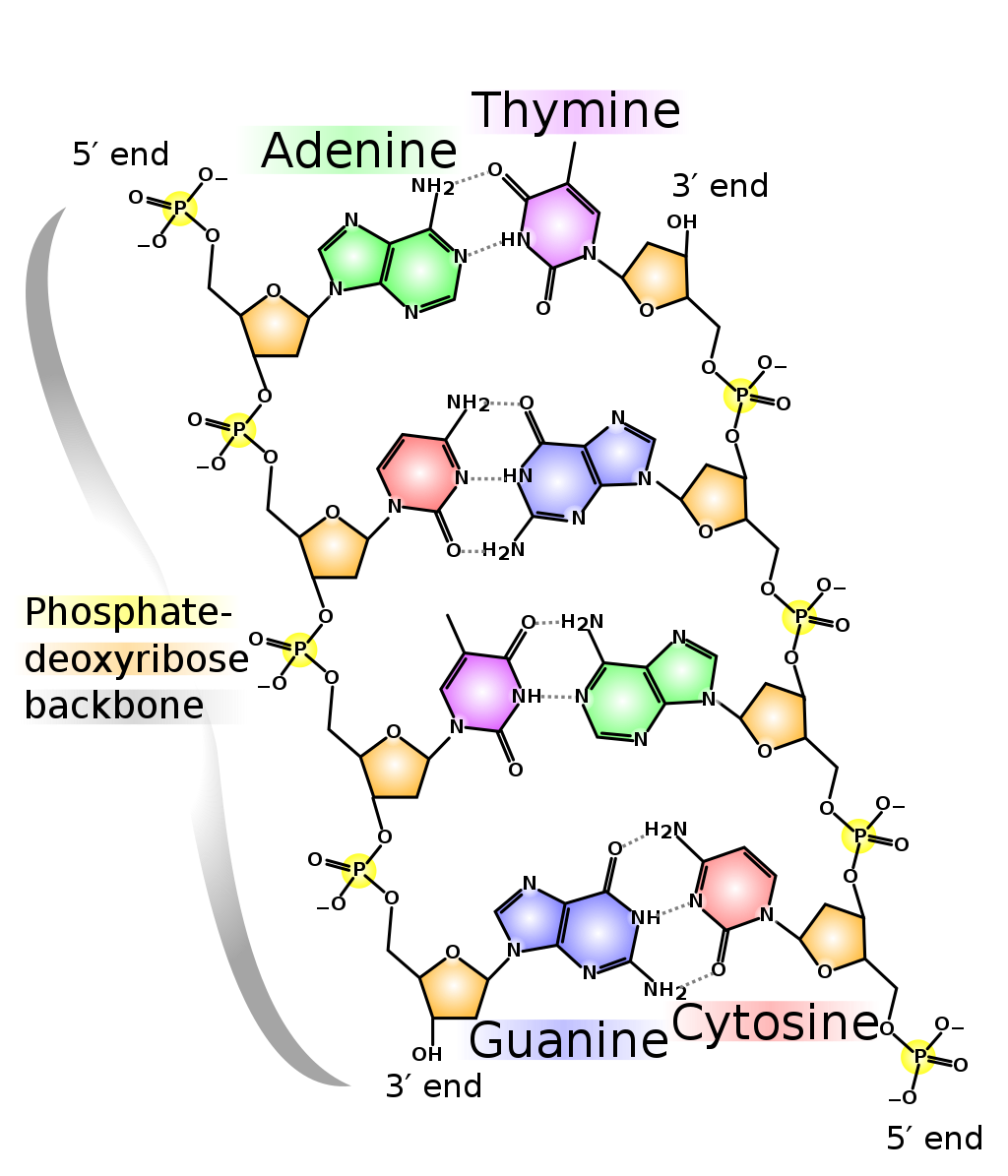
DNAのヌクレオチド(核酸塩基+糖+リン酸の単位)の並び方を、塩基配列と言う。 DNA塩基配列は、A (アデニン)、T (チミン)、G (グアニン)、C (シトシン)の4種類の塩基から構成される。 二本鎖DNAは、AとT、GとCが水素結合していて、その結合の対を「塩基対」という。
塩基配列は、タンパク質のアミノ酸配列に対応しており、 3つの塩基の組み合わせが、20種類のアミノ酸1つずつに対応している。 各アミノ酸に対応する3つの塩基が並ぶ配列情報のことを、「codon (コドン)」という。
例えば、DNA配列で「ATG」、RNA配列で「AUG」が、メチオニン(Met)または開始コドンをコードしている。
seqinrパッケージのインストール
seqinrは、生物学的配列の検索と解析を目指したパッケージである。 生物学的配列(DNAおよびタンパク質)データの探索的データ解析、およびデータの可視化を行うことができる。
Seqinrパッケージは、Gouy, M. et al. (1984) Nucleic Acids Res. 12:121-127に記載されているACNUCシステムで配列データを管理するユーティリティを含んでいる。
それでは、Rを起動して、seqinrパッケージを準備する。
#インストール install.packages("seqinr") #ロード library(seqinr)
seqinrパッケージを使って、DNA配列データを扱う
seqinrパッケージを使った配列処理では、 核酸配列の文字列ではなく、 1つずつの塩基をベクトルデータを使用する。
#任意のDNA塩基配列 (文字列) DNAseq <- "ATGCGATTTTTAGATAATCGTTGGCTACTTAGGGGGGTAGTATGA" DNAseq #[1] "ATGCGATTTTTAGATAATCGTTGGCTACTTAGGGGGGTAGTATGA" #配列の文字列をバラバラにする処理(ベクトルへの変換) DNAseq0 <- strsplit(as.character(DNAseq), NULL)[[1]] DNAseq0 # [1] "A" "T" "G" "C" "G" "A" "T" "T" "T" "T" "T" "A" "G" "A" #[15] "T" "A" "A" "T" "C" "G" "T" "T" "G" "G" "C" "T" "A" "C" #[29] "T" "T" "A" "G" "G" "G" "G" "G" "G" "T" "A" "G" "T" "A" #[43] "T" "G" "A" #あるいは、第2引数に空文字("")を指定するのでもOKです。 DNAseq0 <- strsplit(as.character(DNAseq), "")[[1]] #あるいは、seqinr::s2cでベクトル化する(ベクトルへの変換) seqinr::s2c(DNAseq) # [1] "A" "T" "G" "C" "G" "A" "T" "T" "T" "T" "T" "A" "G" "A" #[15] "T" "A" "A" "T" "C" "G" "T" "T" "G" "G" "C" "T" "A" "C" #[29] "T" "T" "A" "G" "G" "G" "G" "G" "G" "T" "A" "G" "T" "A" #[43] "T" "G" "A"
配列データを使った基本的な処理
配列データを使って、相補鎖、GC含量、タンパク質配列などを求める。
#相補鎖を求める seqinr::comp(DNAseq0, forceToLower = FALSE) # [1] "T" "A" "C" "G" "C" "T" "A" "A" "A" "A" "A" "T" "C" "T" #[15] "A" "T" "T" "A" "G" "C" "A" "A" "C" "C" "G" "A" "T" "G" #[29] "A" "A" "T" "C" "C" "C" "C" "C" "C" "A" "T" "C" "A" "T" #[43] "A" "C" "T" #GC含量の計算 seqinr::GC(DNAseq0) #[1] 0.4 #配列中に出現する回数をカウント seqinr::count(tolower(DNAseq0), wordsize=1) seqinr::count(tolower(DNAseq0), wordsize=2) seqinr::count(tolower(DNAseq0), wordsize=3) #核酸配列をタンパク質配列に変換する seqinr::translate(DNAseq0) # [1] "M" "R" "F" "L" "D" "N" "R" "W" "L" "L" "R" "G" "V" "V" #[15] "*" #文字のベクトルを文字列に変換する seqinr::c2s(DNAseq0) #[1] "ATGCGATTTTTAGATAATCGTTGGCTACTTAGGGGGGTAGTATGA"
seqinr::AAstat 関数
seqinr::AAstat関数で、グラフィカルな表示も可能である。
この関数では、 残基数、物理化学的クラスの割合、理論的等電点を含む単純なタンパク質配列情報の結果を出力する。 また、曖昧なアミノ酸残基は無視される。
#配列データから、各種のタンパク質の統計データを取得する seqinr::AAstat(seqinr::translate(DNAseq0)) #$Compo #* A C D E F G H I K L M N P Q R S T V W Y #1 0 0 1 0 1 1 0 0 0 3 1 1 0 0 3 0 0 2 1 0 #$Prop #$Prop$Tiny #[1] 0.06666667 #$Prop$Small #[1] 0.3333333 #$Prop$Aliphatic #[1] 0.3333333 #$Prop$Aromatic #[1] 0.1333333 #$Prop$Non.polar #[1] 0.6 #$Prop$Polar #[1] 0.3333333 #$Prop$Charged #[1] 0.2666667 #$Prop$Basic #[1] 0.2 #$Prop$Acidic #[1] 0.06666667 #$Pi #[1] 11.69898

補足
seqinr: Biological Sequences Retrieval and Analysis
Exploratory data analysis and data visualization for biological sequence (DNA and protein) data. Seqinr includes utilities for sequence data management under the ACNUC system described in Gouy, M. et al. (1984) Nucleic Acids Res. 12:121-127 <doi:10.1093/nar/12.1Part1.121>.
http://seqinr.r-forge.r-project.org/src/mainmatter/introduction.pdf
https://cran.r-project.org/web/views/Genetics.htmlcran.r-project.org
http://seqinr.r-forge.r-project.org/seqinr_3_1-5.pdf
http://seqinr.r-forge.r-project.org/src/mainmatter/getseqflat.pdf
http://seqinr.r-forge.r-project.org/src/appendix/gencodes.pdf
DNAコドン表
DNAでコドン表を記載してくれてるのは、結構ありがたい。
https://www.genscript.com/tools/codon-tablewww.genscript.com
RNAコドン表
http://nature.cc.hirosaki-u.ac.jp/lab/3/animsci/text_id/Codons.htmlnature.cc.hirosaki-u.ac.jp