
はじめに
Prophetパッケージは、Meta社(当時、Facebook社)が2017年頃に開発した時系列予測のオープンソースのライブラリです。 R実装版もあり、今回そのパッケージを使用しました。
実際、私も実務で経験しましたが、、 時系列データの予測アルゴリズムの構築は途轍もなく困難を伴います。 その行為はまさしく、途方もなく、雲を掴む感じですね。
Prophetパッケージは、そのような時系列モデル構築の難易度を下げて、ユーザーをアシストしてくれます。 また、多くの場合、モデルの細かいチューニングをしなくても、デフォルト設定でも案外良好なアウトプットが得られるのも魅力的なところです。
この記事では基本的な関数紹介が中心ではなくて、より実践的な解析内容を中心に紹介します。 実データとしては、このブログ「京橋のバイオインフォマティシャンの日常」の利用ユーザー数のデータをもとにして、将来のユーザー数の推移予測をやってみました。2022年11月現在、ブログのユーザー数は月で7000-8000人あたりにいます。
また、それに加えて、日経225やビットコインの推移予測の実施事例も紹介したいと思います。
実行環境
macOS Big Sur (バージョン11.5.2) MacBook Air (M1, 2020) チップ Apple M1 メモリ 16GB
Prophetのデータフォーマット
まずは、Prophetのデータ形式についてです。
Prophetのインプット・データには、ds列とy列という、2列のデータを持つ、データフレームを準備します。
ds列 (=datestamp列) は時系列の列で、日付ならYYYY-MM-DD、タイムスタンプなら YYYY-MM-DD HH:MM:SS というスタイルになります。y列は時系列のそれぞれに対応する数値データで、予測したい測定値の過去データとなります。
データフォーマットも、非常にシンプルですね。
関連パッケージの準備
それでは、prophetパッケージをインストールします。
開発者版のprophet(ver 1.1.1)をインストールする方がバグが改善されています。
そのため、CRAN版パッケージ・インストールはスキップしてください。
#環境変数の全削除 rm(list=ls()) #関連パッケージ・インストール pack <- c("devtools", "ggplot2", "dygraphs") install.packages(pack[!(pack %in% unique(rownames(installed.packages())))]) #CRAN版パッケージ・インストール #ver 1.0; 2021-03-30 #pack <- c("prophet") #install.packages(pack[!(pack %in% unique(rownames(installed.packages())))]) #開発者版パッケージ・インストール #ver 1.1.1 インストール from GitHub (2022.09.08) devtools::install_github('facebookincubator/prophet', subdir='R') #ライブラリ準備 library(prophet) library(ggplot2) library(dygraphs) #バージョン確認 packageVersion("prophet") #[1] ‘1.1.1’ #Calc_residuals関数の読み込み source("https://gist.githubusercontent.com/kumeS/486d049718bb981f980db651d550b59b/raw/3480fdfcea0d168952b62dc682558a537a24cf8f/Calc_residuals.R")
また、入力値と構築モデルの残差を計算する、Calc_residuals関数も読み込んでください。
ブログ利用ユーザー数の推移を未来予測する
実行には、prophetパッケージのprophet関数を使います。
prophet関数の最初の引数dfには、過去データのデータフレームを指定します。
このデータフレームは、過去データの日付を含むds列、及び過去データの数値データを含むy列を持つ必要があります。
それでは、実際のこのブログの利用ユーザー数のデータを使って、予測を実行してみます。 この時系列データは「2020/4/1」か「ら2022/11/12」まであります。
また、過去1日間の訪問ユーザー数(y_1day列)、過去7日間の訪問ユーザー数(y_7day列)、過去14日間の訪問ユーザー数(y_14day列)、過去28日間の訪問ユーザー数(y_28day列)の列があります。
過去14日間の訪問ユーザー数(y_14day列)を使って、ブログ利用ユーザー数の推移を予測する
まずは、過去14日間の訪問ユーザー数(y_14day列)のデータに対して、prophetを実行しました。
ここで、増加し続ける周期性を示すデータの予測を行う場合には、 「seasonality.mode = "multiplicative"」を指定します。
また、周期性の誤差を考慮するには、mcmc.samplesというパラメータを設定することで、ベイズ推論を行えます。結構計算時間がかかるので、今回は、デフォルトのMAP推定にしています。
それでは、実行していきます。
#利用者データのURL url <- "https://gist.githubusercontent.com/kumeS/c677d0b3ceb56f74cd109aae6acfd1a8/raw/6cf600582b8ba5bc3812d2a600de959c01548eca/Blog_Users_20200401-20221112.csv" #データの読み込み df <- read.csv(url, header = T) #表示 head(df) # ds y_1day y_7day y_14day y_28day #1 2020/4/1 0 0 0 0 #2 2020/4/2 0 0 0 0 #3 2020/4/3 0 0 0 0 #4 2020/4/4 0 0 0 0 #5 2020/4/5 0 0 0 0 #6 2020/4/6 0 0 0 0 #14dayデータを使用する df_14day <- data.frame(ds=as.Date(df$ds), y=as.numeric(sub(",", "", df$y_14day)), row.names=1:nrow(df)) #表示 head(df_14day) # ds y #1 2020-04-01 0 #2 2020-04-02 0 #3 2020-04-03 0 #4 2020-04-04 0 #5 2020-04-05 0 #6 2020-04-06 0 #Prophet実行 m <- prophet(df=df_14day, growth = "linear", n.changepoints = 100, changepoint.range = 1, changepoint.prior.scale=0.05, seasonality.mode = "multiplicative", interval.width = 0.95) #クラス表示 class(m) #[1] "prophet" "list"
prophet関数を実行して、mというモデル変数を出力します。
次に、make_future_dataframe関数を使って、予測する期間のデータフレームを生成します。
freqの引数としては、day、week、month、quarter、yearなどを選択できます。
さらには、モデルと予測期間のデータフレームをpredict関数に渡して、 plot関数などを使って予測結果を可視化します。
#365日分のデータフレーム作成 future <- make_future_dataframe(m, periods = 365, freq = "day") #モデル予測 forecast <- predict(m, future) #末尾表示 tail(forecast[c('ds', 'yhat', 'yhat_lower', 'yhat_upper')]) # ds yhat yhat_lower yhat_upper #1316 2023-11-07 6524.384 5941.722 7090.318 #1317 2023-11-08 6533.519 5921.415 7090.767 #1318 2023-11-09 6536.082 5960.249 7101.341 #1319 2023-11-10 6554.383 5971.351 7139.919 #1320 2023-11-11 6564.437 5974.211 7160.411 #1321 2023-11-12 6576.142 5978.119 7156.932 #予測結果のプロット plot(m, forecast) #文字化け対策 Sys.setlocale("LC_TIME", "en_US") #トレンド結果 prophet_plot_components(m, forecast) #実測と予測された結果: 残差の計算 Calc_residuals(df_14day$y, forecast$yhat[1:nrow(df_14day)]) # mse mae rmse MAPE R2 #1 1666.788 28.3356 40.8263 12.6803 0.9987
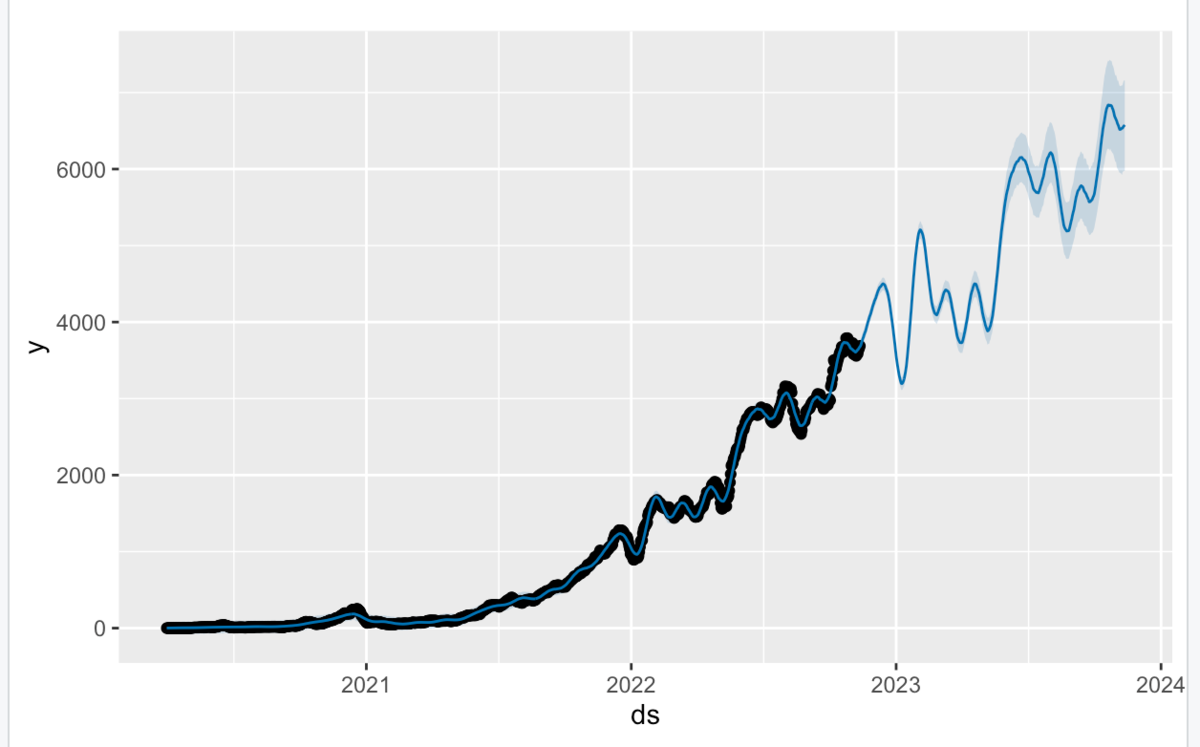
青線の予測結果から、2週間ベースで、2022年末に4500人で、2023年明けに5000人を超えることが期待されますね。 また、2023年6月ごろには6000人を目指せそう結果になってますね。
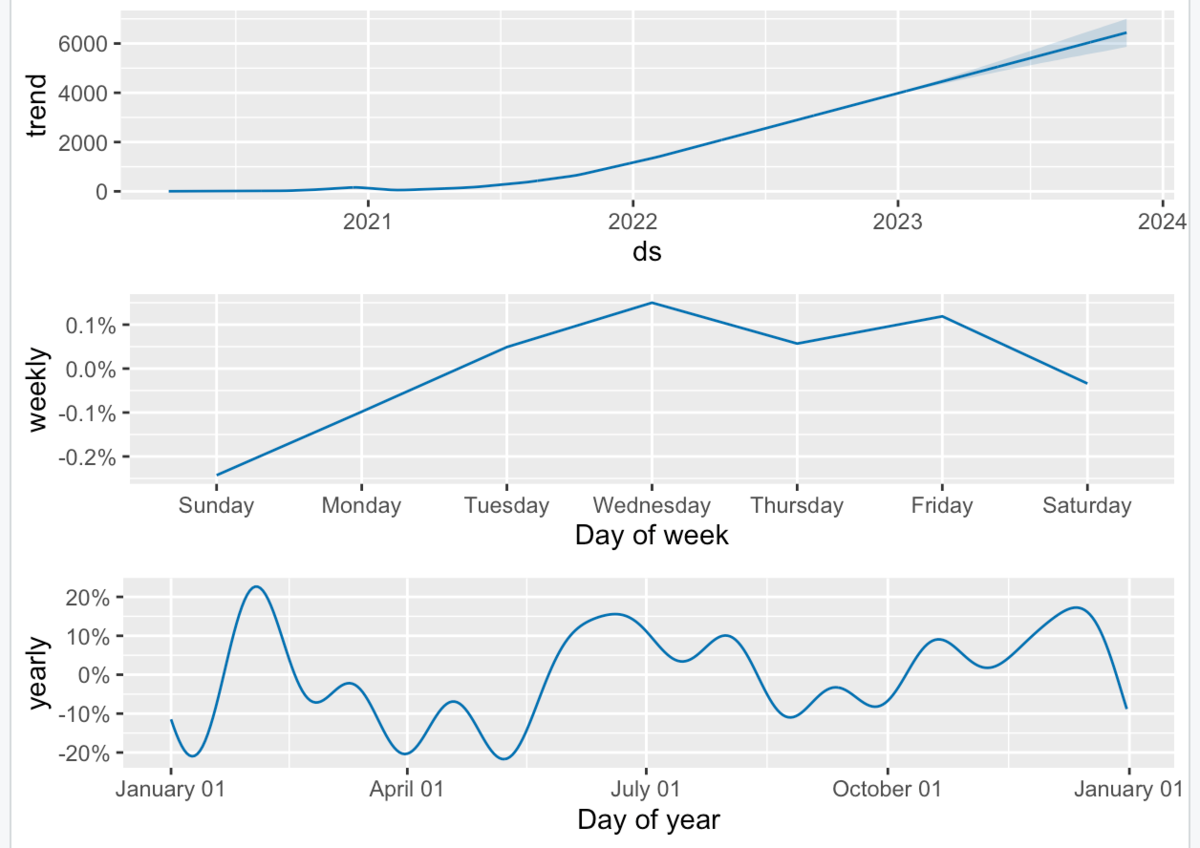
トレンドは、2021年の後半から上昇トレンドにありますね。 水曜日と金曜日に多い傾向にありますね。
他のプロット方法について
add_changepoints_to_plot関数で、潜在的変化点を重ね合わせできます。 また、plot_forecast_componentでは、特定の成分をプロットします。
dyplot.prophetでは、dygraphsパッケージによるインタラクティブなプロットは可能です。
#重要な変化点の重ね合わせプロット plot(m, forecast) + add_changepoints_to_plot(m) ##特定の成分をプロットする #yhat plot_forecast_component(m, forecast, name="yhat") #trend plot_forecast_component(m, forecast, name="trend") #dyplotによるインタラクティブ・プロット dyplot.prophet(m, forecast)
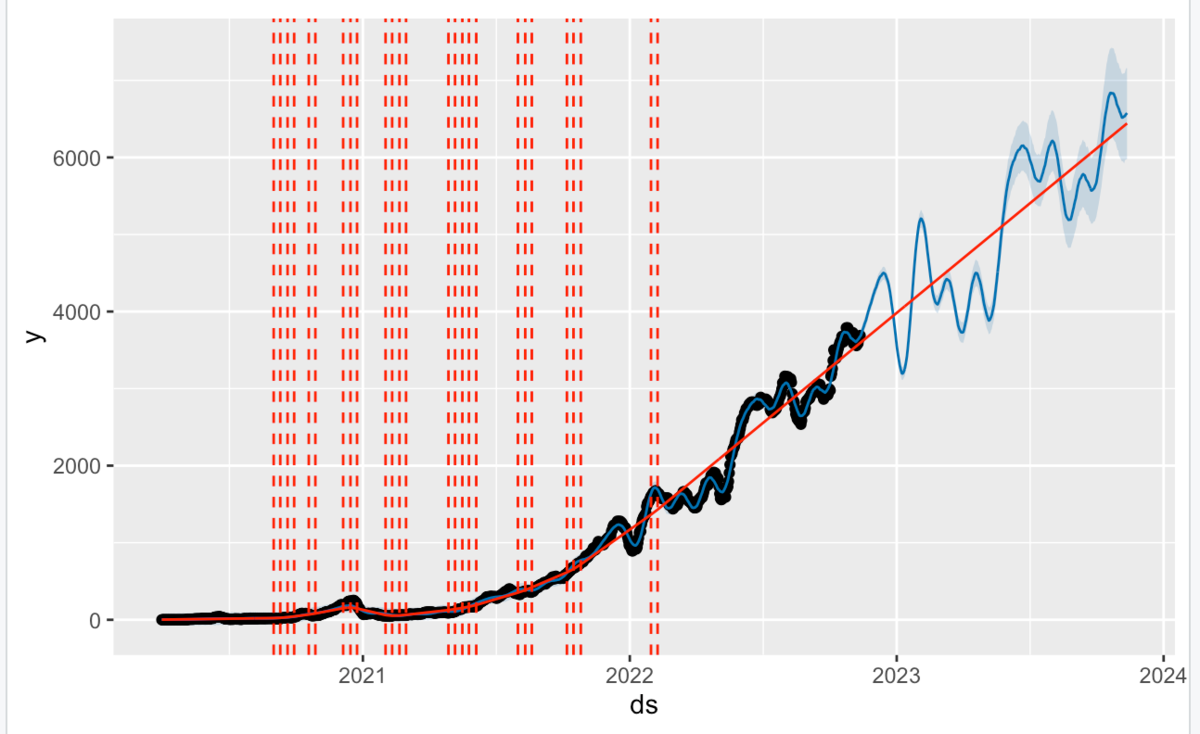
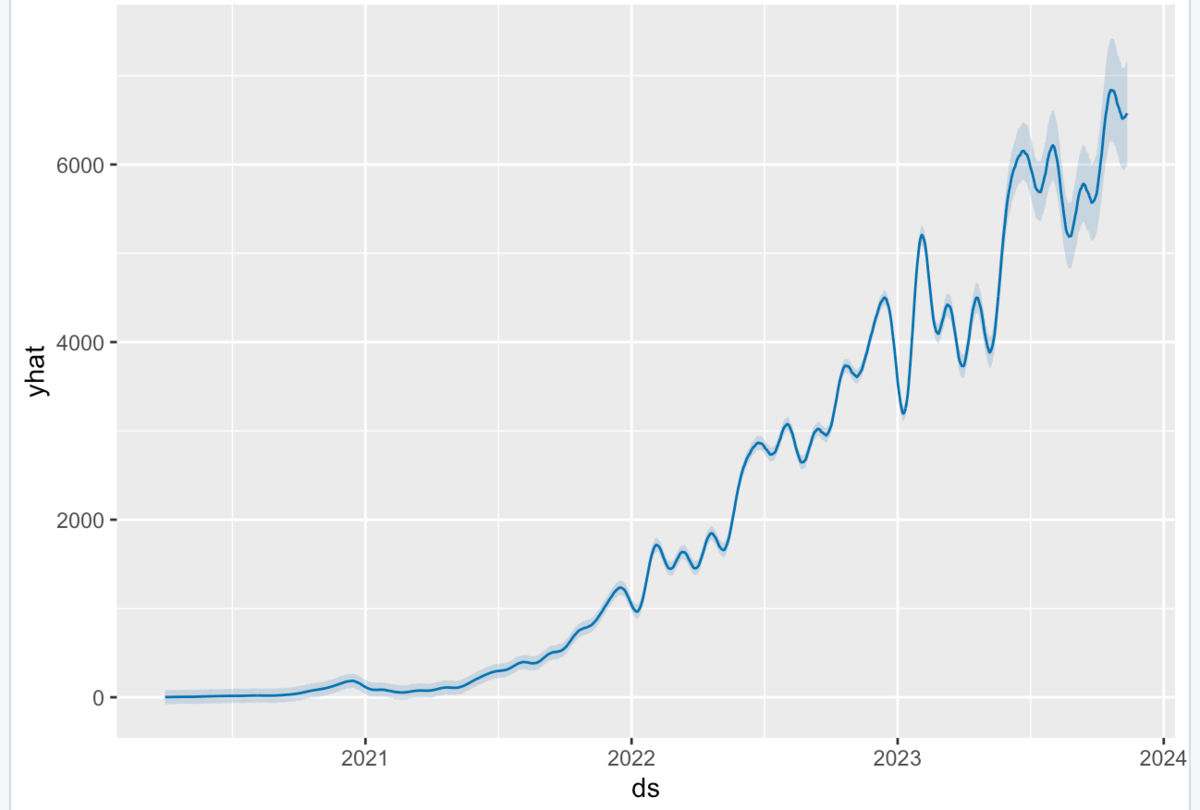
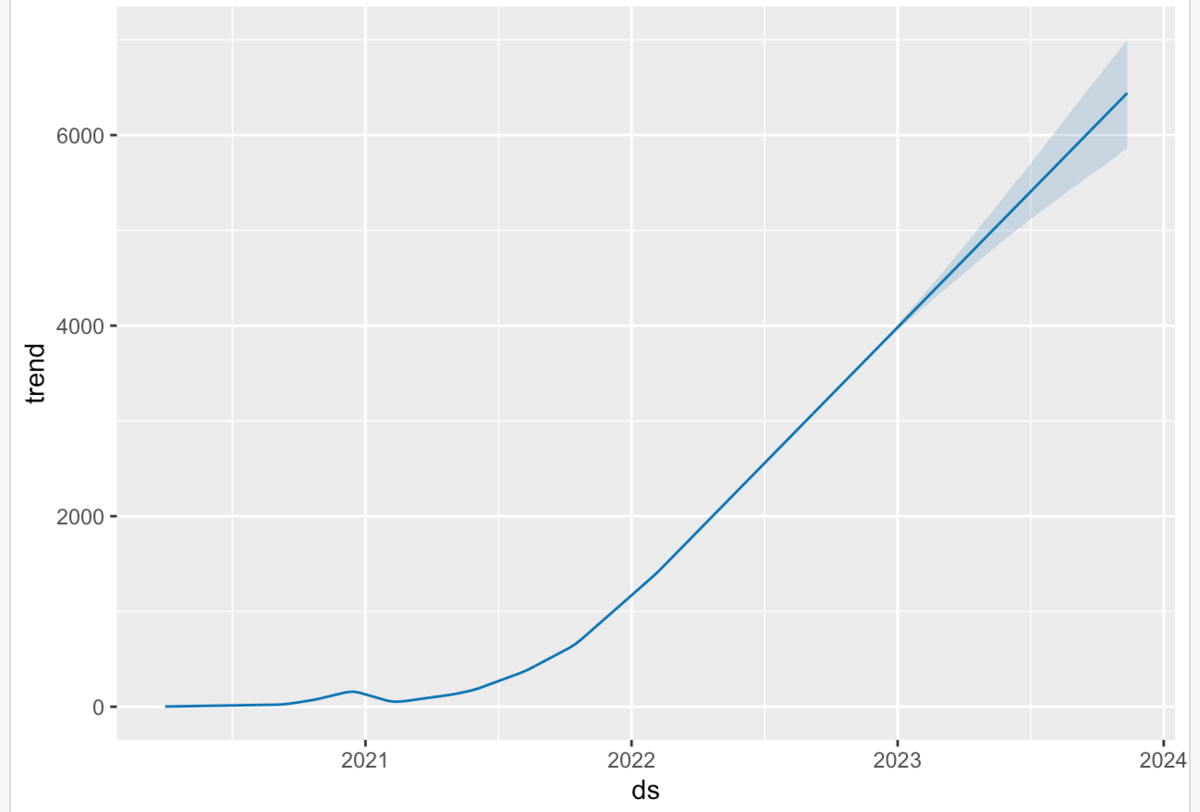
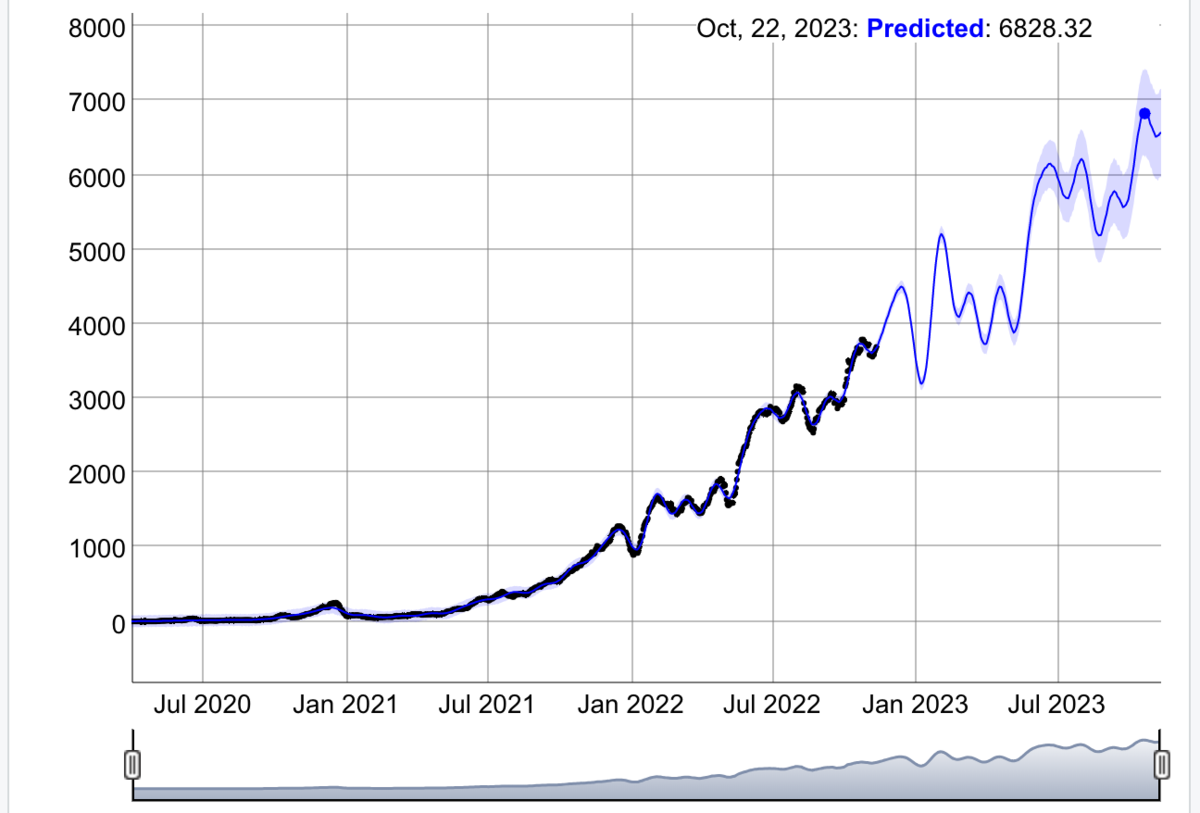
dyplot.prophet関数は、インタラクティブにプロットできて、使い勝手も良いですね。
過去28日間の訪問ユーザー数(y_28day列)を使って、ブログ利用ユーザー数の推移を未来予測する
次に、過去28日間の訪問ユーザー数(y_28day列)を使って、prophetを実行しました。
ここでは、少し実行内容を省略しています。
#利用者データのURL url <- "https://gist.githubusercontent.com/kumeS/c677d0b3ceb56f74cd109aae6acfd1a8/raw/6cf600582b8ba5bc3812d2a600de959c01548eca/Blog_Users_20200401-20221112.csv" #データの読み込み df <- read.csv(url, header = T) #28dayデータを使用する df_28day <- data.frame(ds=as.Date(df$ds), y=as.numeric(sub(",", "", df$y_28day)), row.names = 1:nrow(df)) #Prophet実行 m <- prophet(df=df_28day, growth = "linear", n.changepoints = 100, changepoint.range = 1, changepoint.prior.scale=0.05, interval.width = 0.95, seasonality.mode = "multiplicative") #365日分のデータフレーム作成 future <- make_future_dataframe(m, periods = 365, freq = "day") #モデル予測 forecast <- predict(m, future) #結果のプロット plot(m, forecast) + add_changepoints_to_plot(m) #dyplotによるインタラクティブ・プロット dyplot.prophet(m, forecast) #実測と予測された結果: 残差の計算 Calc_residuals(df_28day$y, forecast$yhat[1:nrow(df_28day)]) # mse mae rmse MAPE R2 #1 998.6104 20.8671 31.6008 6.7593 0.9998
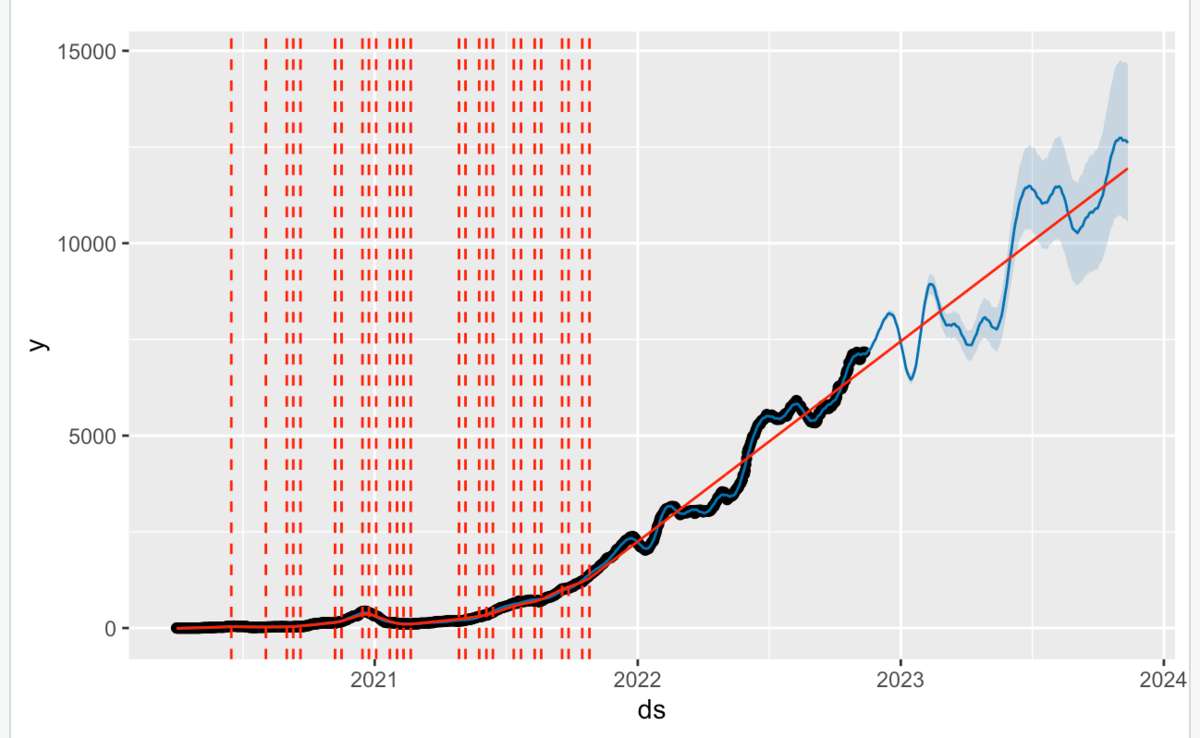
28日の利用者数の予測結果は、14日の利用者数の予測結果の2倍の値を示します。
来年1月初めに、利用者数が激減しているけども、何か対策はあるのかな。。
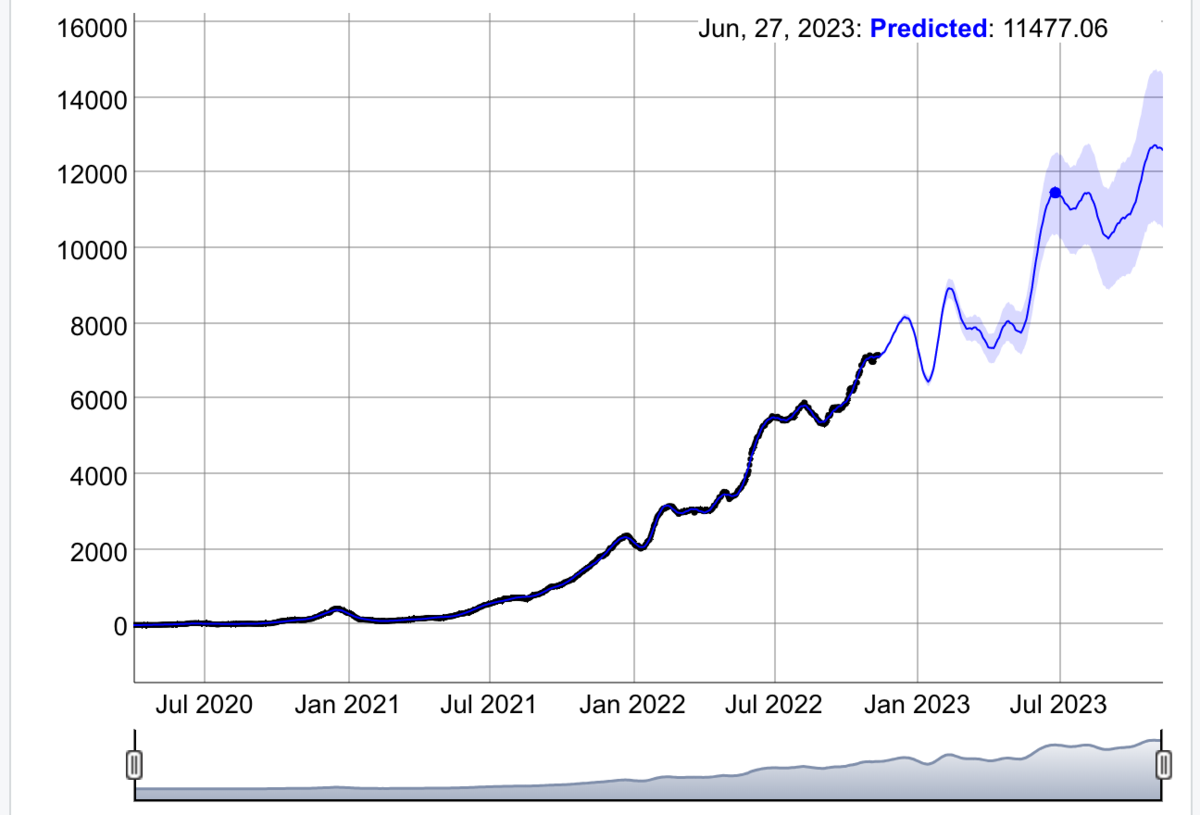
何方にせよ、2023年もアップ・トレンドを期待したいです。
日経225インデックスの将来推移を予測してみたところ
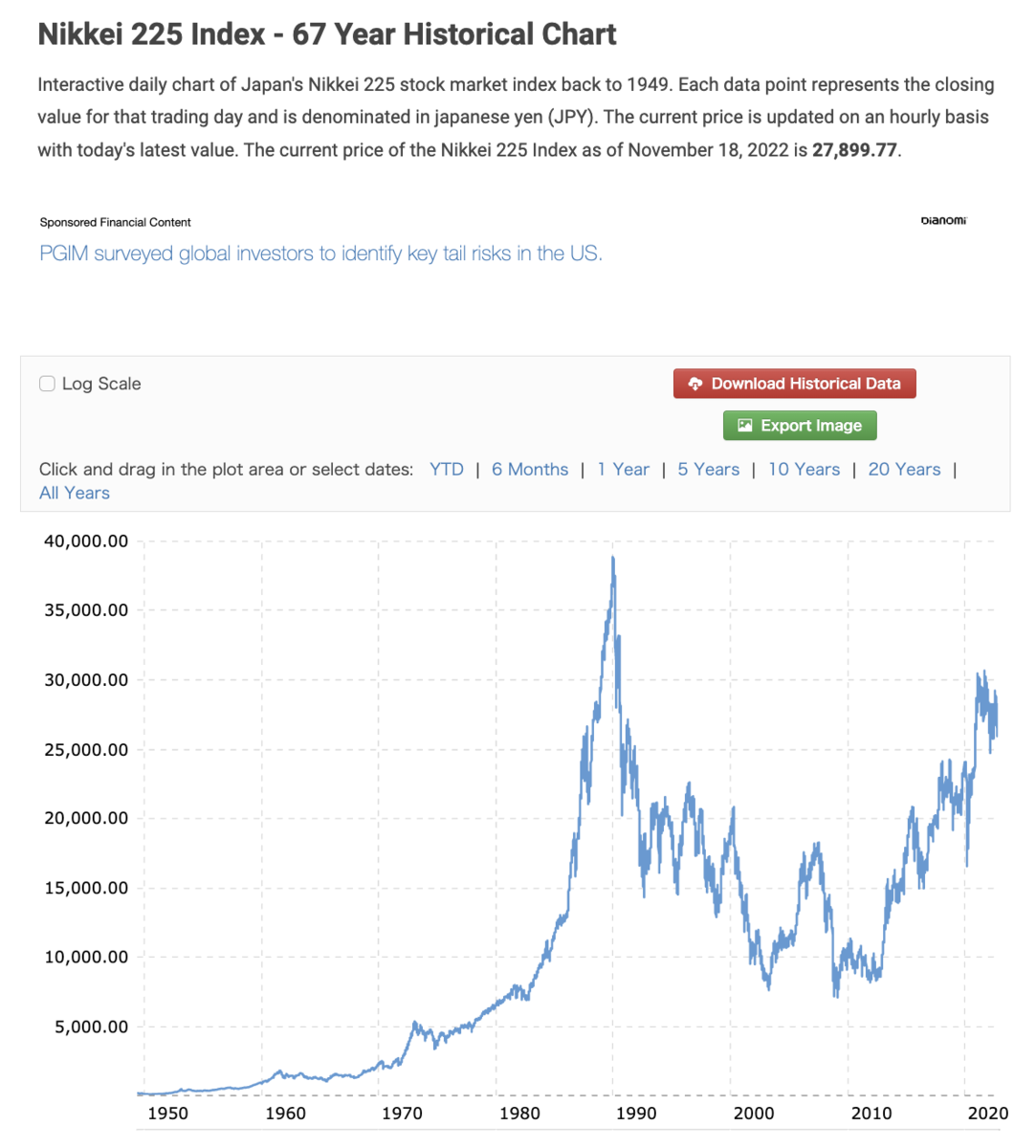
最近、www.macrotrends.netで、日経225インデックスの67年間のチャートデータを見つけました。
ちょうどいいデータなので、今回使ってみることにしました。
まずは、Gistに成形した日経225インデックスのチャートデータをアップしていますので、それをダウンロードします。
#ダウンロードデータURLの定義 url <- "https://gist.githubusercontent.com/kumeS/0b901711f87e5a6854a6b354559b11ff/raw/d018a8700d150d43a528a347ee0ffb73cee322c8/nikkei-225-index-67-year-historical-chart-data.csv" #日経225データの読み込み df <- read.table(url, sep=",", header = TRUE) #dyplotによるインタラクティブ・プロット df0 <- df rownames(df0) <- df0$ds dygraph(df0) %>% dyRangeSelector()
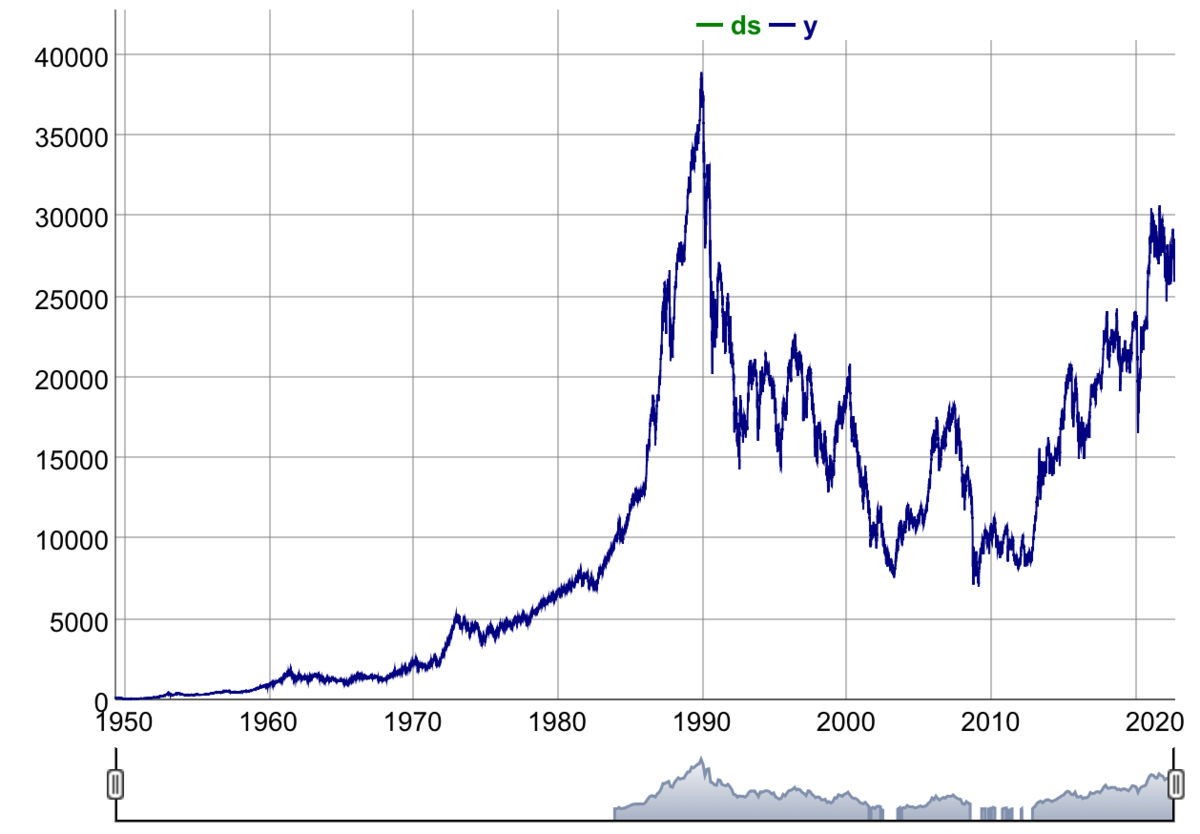
2012年以降のデータで、prophetで株価トレンドを予測する
日経225の2012年以降のデータを使用って、prophetで株価トレンドを予測してみました。
changepoint.prior.scaleは、潜在的変化点の自動選択の柔軟性を調整するパラメータです。 大きな値を設定すると、多くの変化点が選択され、小さな値を設定すると、変化点は選択され難くなります。今回、そのスケール値を0.85に変えています。
また、make_future_dataframe関数では、24週間分のデータフレームを作成しています。
#2012年以降のデータを使用する df2012 <- df[df$ds > "2012-01-01",] #表示 head(df2012) # ds y #15605 2012-01-04 8560.11 #15606 2012-01-05 8488.71 #15607 2012-01-06 8390.35 #15608 2012-01-10 8422.26 #15609 2012-01-11 8447.88 #15610 2012-01-12 8385.59 #Prophet実行 m <- prophet(df=df2012, growth = "linear", n.changepoints = 50, changepoint.range = 1, changepoint.prior.scale=0.85, interval.width = 0.8, seasonality.mode = "multiplicative") #24週分のデータフレーム作成 future <- make_future_dataframe(m, periods = 24, freq="week") #モデル予測 forecast <- predict(m, future) #dyplotによるインタラクティブ・プロット dyplot.prophet(m, forecast)

まぁ、フィットが悪いんだけど、年明けから日経225が下がったら面白いね。 ふと思うと、アップトレンドをではないので、seasonality.mode = "additive"のほうがフィットは良いのかも・・・
ビットコイン(BTC)の価格推移を予測してみたところ
ここでは、getBTC関数を使って、 2010年7月18日から今日(現在、2022年11月20日)までのBTCの日足データを取得します。
それで、ビットコインの取得データは、2017年以降のデータを使用します。
#BTCのデータ取得 source("https://gist.githubusercontent.com/kumeS/c466e97d42f6facbb8ba5a22ed361bf4/raw/07728e5e4810e53aa8bdcc411ac51603943761df/getBTC.R") #BTCのデータ取得 BTC <- getBTC() BTC0 <- BTC[,c("Date", "Close")] colnames(BTC0) <- c("ds", "y") #2017年以降のデータを使用する BTCdata <- BTC0[BTC0$ds > "2020-01-01",]
やっぱり、仮想通貨のように値動きの激しいデータは、パラメータ・チューニングに苦戦しますね。それでもかなりマシですけども。。。
アップトレンドで無いデータということで、seasonality.modeの引数はadditiveにしています。
#Prophet実行 m <- prophet(df=BTCdata, growth = "linear", n.changepoints = 250, changepoint.range = 1, changepoint.prior.scale=0.5, interval.width = 0.8, seasonality.mode = "additive") #30日分のデータフレーム作成 future <- make_future_dataframe(m, periods = 30, freq="day") #モデル予測 forecast <- predict(m, future) #dyplotによるインタラクティブ・プロット dyplot.prophet(m, forecast)
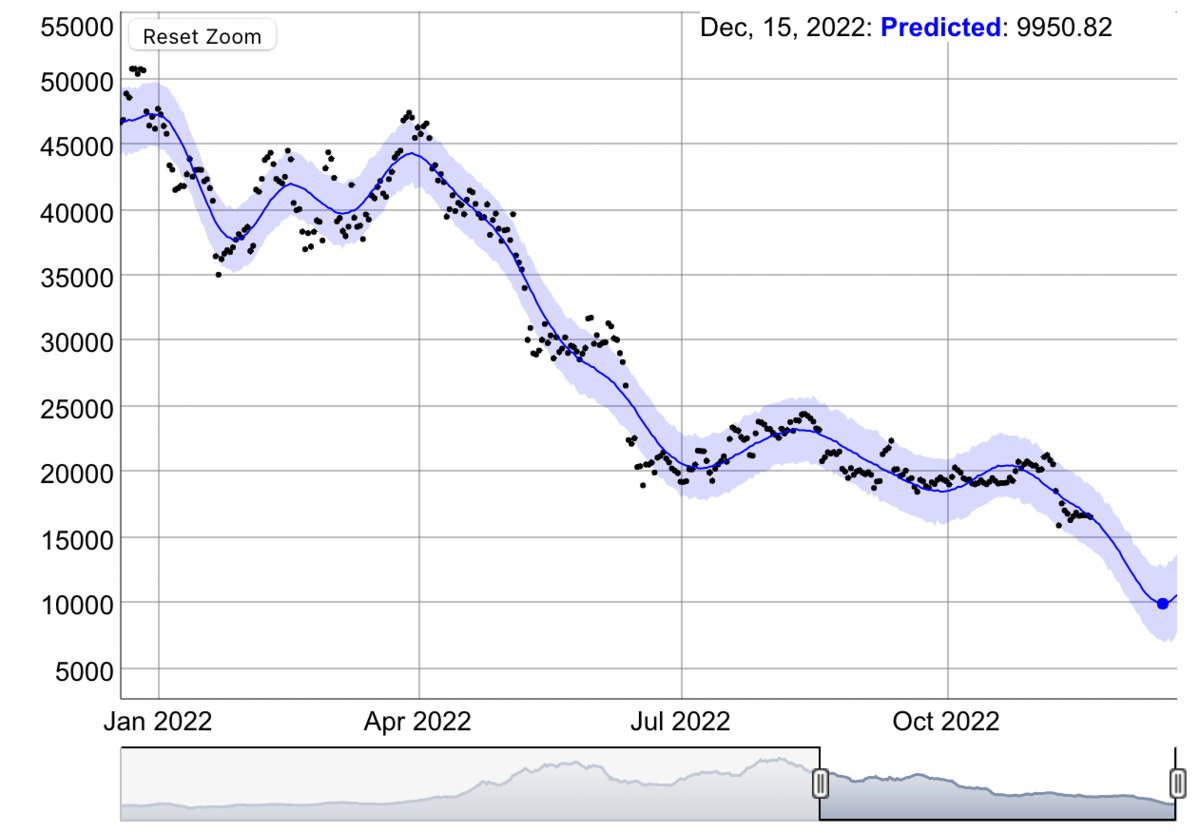
色々とパラメータ調整したからかも知れませんが、、 この結果は、興味深いですね。
ビットコインが10000ドルあたりで反転するのか、どうかですね。
まとめ
現在、ブログのユーザー数は月で7000-8000人を推移してますが、今後どう推移してくるのか?、Prophetでの予想通りに増えてくるのか?、1万人の大台を超えてくるのか、楽しみですね。今後、実際のデータとの比較もできるとさらに面白そうだ。。。
あとは、弱気相場も大詰めで、ビットコインの底値がどのあたりになるかも気になりますね。時系列予測がどこまで使えるか、気になりますよね。
補足
Calc_residuals関数
このCalc_residuals関数では、 MSE(平均二乗誤差)、MAE(平均絶対誤差)、RMSE(二乗平均平方根誤差)、MAPE(平均絶対パーセント誤差)、およびR2(決定係数)を計算します。
Calc_residuals <- function(original, predicted, digits=4){ #diff d0 <- original - predicted #MSE d1 <- mean((d0)^2) #MAE d2 <- mean(abs(d0)) #RMSE d3 <- sqrt(mean((d0)^2)) #MAPE d4a <- abs((d0/original)) d4b <- mean(d4a[!is.infinite(d4a)])*100 #R2 d5 <- round(1-(sum((d0)^2)/sum((original-mean(original))^2)), digits) return(data.frame(mse=round(d1, digits=digits), mae=round(d2, digits=digits), rmse=round(d3, digits=digits), MAPE=round(d4b, digits=digits), R2=round(d5, digits=digits), row.names = 1)) }
prophet関数のオプション
| 引数 | 概要 |
|---|---|
| df | (オプション) 履歴を含むデータフレーム。ds (日付型) と y (時系列) の列を持たなければならない。成長がロジスティックである場合、dfは、各dsの容量を指定する列capも持っていなければならない。モデルをフィットさせるにはfit.prophet(m, df)を使ってください。 |
| growth | 文字列(String) 'linear', 'logistic', または 'flat' で、線形、ロジスティック、またはフラットトレンドを指定します。 |
| changepoints | 潜在的なチェンジポイントを含む日付のベクトル。指定しない場合、変化点候補は自動的に選択されます。 |
| n.changepoints | 含めるべき潜在的な変化点の数。入力 'changepoints' が与えられている場合は使用されません。changepoints' が与えられない場合、 df$ds の最初の 'changepoint.range' の割合から一様に n.changepoints 潜在的な変化点が選択されます。 |
| changepoint.range | トレンド変化点が推定される履歴の割合。デフォルトでは、最初の 80 'changepoints'が指定された場合、0.8 となります。 |
| yearly.seasonality | 年間の季節性をフィットさせる。auto', TRUE, FALSE, あるいは生成するフーリエ項の数を指定することができます。 |
| weekly.seasonality | 週ごとの季節性をフィットさせる。auto', TRUE, FALSE, あるいは生成するフーリエ項の数を指定することができます。 |
| daily.seasonality | 日次の季節性をフィットさせる。auto', TRUE, FALSE, あるいは生成するフーリエ項の数を指定することができます。 |
| holidays | holiday (文字) および ds (日付型) の列と、休日として含める日付を指定する lower_window および upper_window の列を持つデータフレームです。また、オプションでprior_scaleカラムを持ち、各祝日の事前スケールを指定することができます。 |
| seasonality.mode | 'additive' (default) or 'multiplicative'. |
| seasonality.prior.scale | 季節性モデルの強さを調節するパラメータ。大きな値を設定すると、より大きな季節変動に対応できるようになり、小さな値を設定すると、季節性が弱くなる。個々の季節性に対して add_seasonality を用いて指定することができる。 |
| holidays.prior.scale | 休日入力で上書きされない限り、休日成分モデルの強さを調節するパラメータ。 |
| changepoint.prior.scale | チェンジポイントの自動選択の柔軟性を調整するパラメータ。大きな値を設定すると多くのチェンジポイントが選択され、小さな値を設定するとチェンジポイントはほとんど選択されません。 |
| mcmc.samples | 整数(Integer)、 0より大きい場合,指定された数のMCMCサンプルで完全なベイズ推定を行います.0の場合, MAP推定を行います. |
| interval.width | 数値(Numeric)、予測に提供される不確実性区間の幅。mcmc.samples=0の場合、これは外挿された生成モデルのMAP推定値を使用したトレンドの不確実性のみとなる。mcmc.samples>0の場合、これは季節性の不確実性を含むすべてのモデルパラメータにわたって統合される。 |
| uncertainty.samples | 不確実性区間を推定するために使用されるシミュレーション描画の数。この値を0またはFalseに設定すると、不確実性推定が無効となり、計算が高速化されます。 |
| fit | true/false, FALSE の場合、モデルは初期化されるが、フィットしない。 |
make_future_dataframe関数のオプション
| 引数 | 概要 |
|---|---|
| m | Prophet モデルオブジェクト |
| periods | 将来予測を行う期間数。 |
| freq | 'day', 'week', 'month', 'quarter', 'year', 1(1 sec), 60(1 minute) or 3600(1 hour). |
| include_history | true/false; 予測用のデータフレームに過去の日付を含めます。 |
参考資料
www.slideshare.net