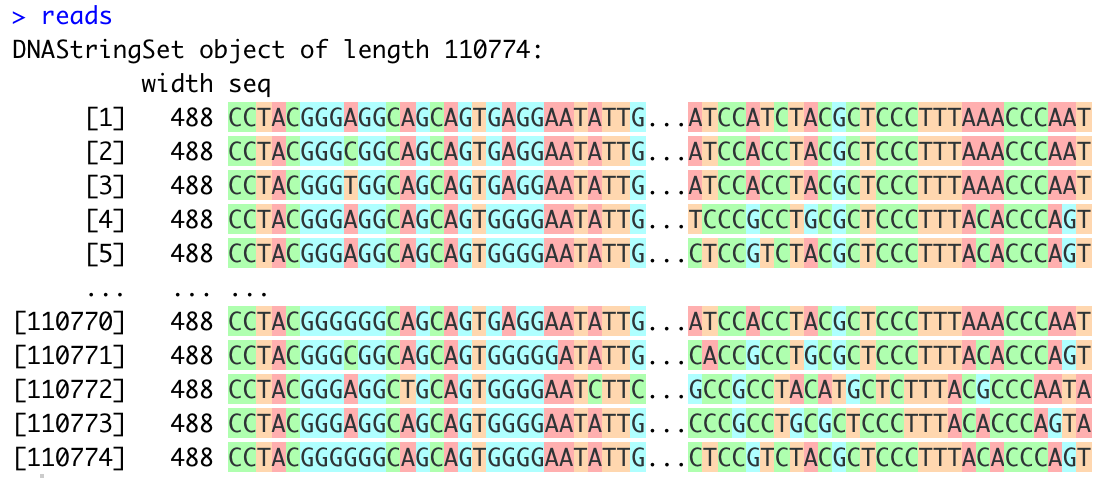
SRA Toolkitの設定
SRA Toolkitの設定は、以前の記事を参考のこと。
prefetchコマンドについて
prefetchは、SRA(Sequence Read Archive)、dbGaP、ADSPデータのコマンドライン・ダウンロードを行うSRA Toolkit内のツールである。
prefetchコマンドで、NCBIのRun ID・アクセッション番号を指定すると、 所定のSRAファイルをダウンロードを行うことができる。 SRAファイルというのは、シークエンスの生データの保存形式の1つである。
ローカルにダウンロードされた、SRAファイルは、
以前紹介した、fastq-dumpコマンドを使うことで、
FASTQ形式のファイルへと変換できる。
また、--option-fileオプションによるファイル参照を用いることで、
複数のSRAファイルを1回のコマンド実行でダウンロードできる。
prefetchの基本形
まずは、prefetchのUsageを以下に示す。
Usage: prefetch [options] <path/SRA file | path/kart file> [<path/file> ...] prefetch [options] <SRA accession> prefetch [options] --list <kart_file>
prefetchの引数に、Run ID(SRAアクセッション番号)を指定して実行するのがメインの使い方となる。
以下に、Run ID、SRR17327096での実行結果を示した。
#SRR17327096のダウンロード prefetch SRR17327096 #2022-01-04T14:52:02 prefetch.2.11.2: Current preference is set to retrieve SRA #Normalized Format files with full base quality scores. #2022-01-04T14:52:03 prefetch.2.11.2: 1) Downloading 'SRR17327096'... #2022-01-04T14:52:03 prefetch.2.11.2: SRA Normalized Format file is being retrieved, #if this is different from your preference, it may be due to current file availability. #2022-01-04T14:52:03 prefetch.2.11.2: Downloading via HTTPS... #2022-01-04T14:52:10 prefetch.2.11.2: HTTPS download succeed #2022-01-04T14:52:10 prefetch.2.11.2: 'SRR17327096' is valid #2022-01-04T14:52:10 prefetch.2.11.2: 1) 'SRR17327096' was downloaded successfully #2022-01-04T14:52:10 prefetch.2.11.2: 'SRR17327096' has 0 unresolved dependencies #ヘッド表示 head ./SRR17327096/SRR17327096.sra #NCBI.sra???Oqlockܥ?a$md֥?am"cur֥?a$4??md5֥?a$?)tblԥ?amSEQUENCE֥?am??col֥?am?!B`ALTREAD֥?am?#EX{??data֥?a$8$@#idx֥?a$((idx0֥?a$idx1֥?a$? #md֥?am"cur֥?a$jmd5֥?a$T?QUALITY֥?am?#EX{??data֥?a$(?X?idx֥?a$x(idx0֥?a$idx1֥?a$0?idx2֥?a$p?md֥?am"cur֥?a$ #?md5֥?a$h?READ֥?am?#EX{??data֥?a$D?AZ?idx֥?a$(idx0֥?a$idx1֥?a$??idx2֥?a$T?md֥?am"cur֥?a$??md5֥?a$|? #SPOT_GROUP֥?am?#EX{??data֥?a$xG?cidx֥?a$P(idx0֥?a$idx1֥?a$??idx2֥?a$??md֥?am"cur֥?a$,jmd5֥?a$@?md֥?#am"cur֥?a$??8fmd5֥?a$?)00??Y????"??c???W??a2fa47b25ad3fc0d8ffac2743996d730 *md/cur #000dbe6a12f6b54989dfd016f340d3bb340 *md/cur #000?tX߯tx??MD5CNTXT1234?#Eg?????ܺ?vT2?tX߯tx???tX߯tx??MD5CNTXT1234?#Eg?????ܺ?vT2?tX߯tx???tX߯tx??MD5CNTXT1234?#Eg?????ܺ?vT2?tX߯tx???? #row-len?schematypeINSDC:2na:packedversion 1;typedef B1 INSDC:2na:packed[2];alias INSDC:2na:packed INSDC:dna:2na;alias INSDC:2na:packed #NCBI:2na;06488d0d60f6f5ba40f1f5e0a9252b2ec *md/cur #d1f0cf0771514cd3964222dab43dd0a1 *idx #1c7d9a18aba301aa0419d34a0c853fd9 *idx1 #d41d8cd98f00b204e9800998ecf8427e *idx0 #32ce55e80d76d7db348d80134f20ff85 *idx2
実行の結果、ローカルディレクトリに「SRR17327096」フォルダが生成され、 その中に「SRR17327096.sra」がダウンロードされる。 「SRR17327096.sra」は、約 17.7 MBのバイナリファイルである。
prefetchの代表的なオプション
ここでは、prefetchでよく使われるオプションを表にまとめた。
| オプション | 概要 |
|---|---|
-h |
すべてのオプション、一般的な使用法、およびバージョン情報を表示 |
-V |
プログラムのバージョンを表示 |
-f |
オブジェクトのダウンロードを強制 |
-l |
kartファイルの内容をリストアップ |
-s |
ターゲットファイルサイズで kart ファイルの内容をリストアップ |
-N |
ダウンロードする最小ファイルサイズをKB単位で指定 |
-X |
ダウンロードする最大ファイルサイズをKB単位で指定 |
-a |
ascp プログラムと秘密鍵ファイル (asperaweb_id_dsa.openssh) へのパス |
-p |
ダウンロードの進行状況を表示 |
--option-file |
ファイルから、オプションやパラメータを読み込む |
複数のSRAファイルを一度にダウンロードする
NCBIのSequence Read Archiveでは、 Studyごとに一連のAccession Listが紐づけられている。 例えば、Run ID、SRR17327096が含まれる StudyのすべてのRunデータを取得することにしてみる。
Accession Listを取得するために、 まずはNCBIのSRR17327096サイトに行く。 そこで、Studyの横にある、All runsをクリックする。
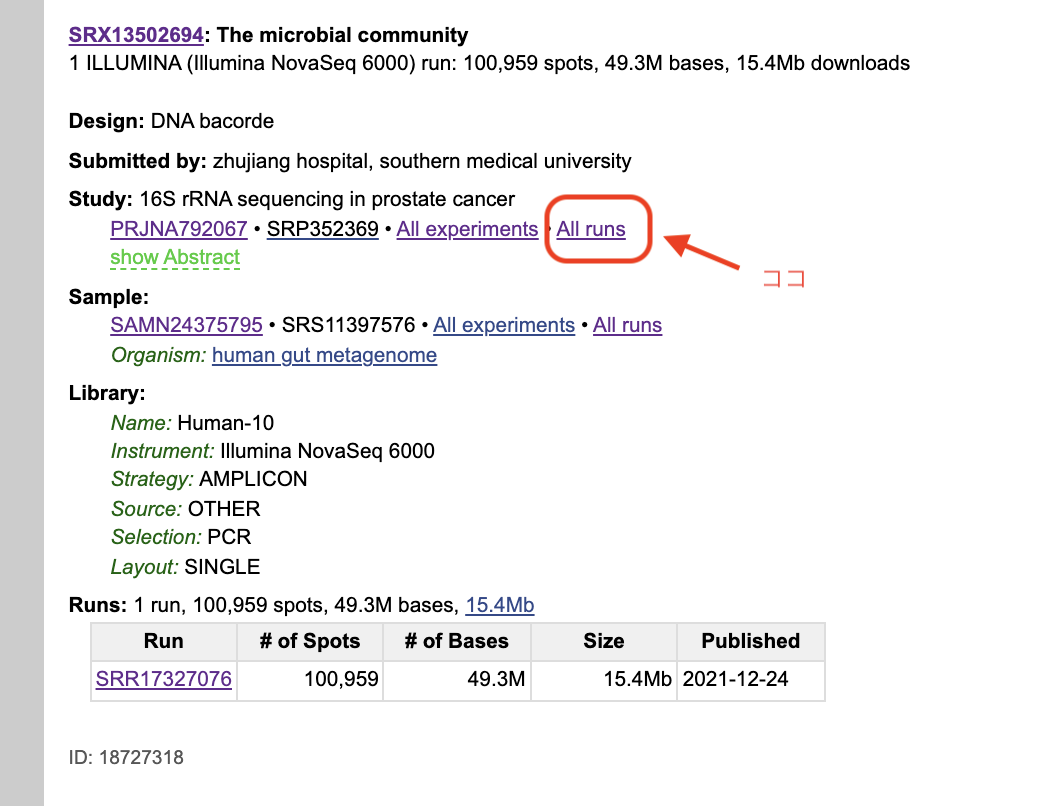
次のページで、DownloadのAccession Listをクリックすると、
一連のRun IDが列挙された、SRR_Acc_List.txtがダウンロードされる。

このBioProject、PRJNA792067では、
トータル 55 Run分のデータが含まれている。次の画像では、SRR_Acc_List.txtの一部を表示させた。

55 Run分はトライアルにしては、ちょっと多過ぎるので、 上から3 lineだけを取り出して、別名のファイル(e.g. SRR_Acc_ListR.txt)を作成する。
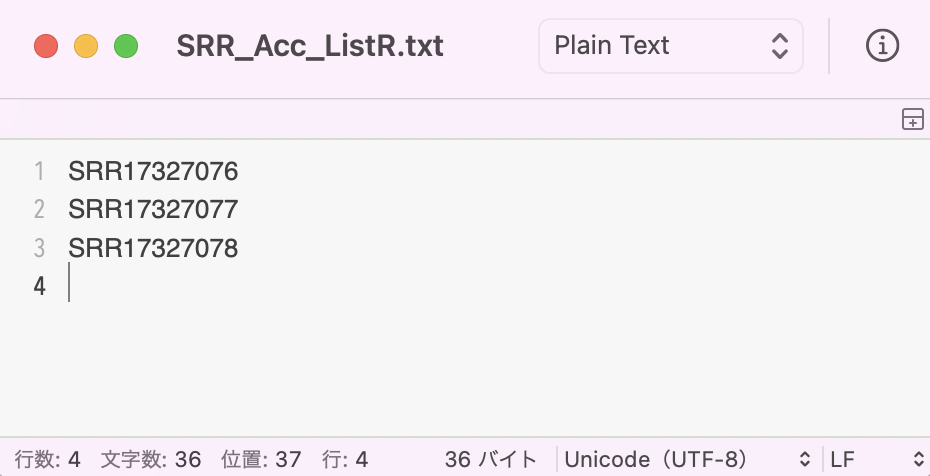
この時の注意ポイントとして、
txtファイルの最終行に、必ず空行を入れておくこと。
prefetchコマンド実行の際には、
--option-fileにAccession Listを指定することで、
複数のSRAファイルを一度にダウンロードできる。
以下に、SRR17327076、SRR17327077、SRR17327078を指定した時の実行結果を示す。
prefetch --option-file SRR_Acc_ListR.txt #2022-01-04T15:13:53 prefetch.2.11.2: Current preference is set #to retrieve SRA Normalized Format files with full base quality scores. #2022-01-04T15:13:54 prefetch.2.11.2: 1) Downloading 'SRR17327076'... #2022-01-04T15:13:54 prefetch.2.11.2: SRA Normalized Format file #is being retrieved, if this is different from your preference, #it may be due to current file availability. #2022-01-04T15:13:54 prefetch.2.11.2: Downloading via HTTPS... #2022-01-04T15:14:01 prefetch.2.11.2: HTTPS download succeed #2022-01-04T15:14:01 prefetch.2.11.2: 'SRR17327076' is valid #2022-01-04T15:14:01 prefetch.2.11.2: 1) 'SRR17327076' was downloaded successfully #2022-01-04T15:14:01 prefetch.2.11.2: 'SRR17327076' has 0 unresolved dependencies #2022-01-04T15:14:02 prefetch.2.11.2: Current preference is set to #retrieve SRA Normalized Format files with full base quality scores. #2022-01-04T15:14:03 prefetch.2.11.2: 2) Downloading 'SRR17327077'... #2022-01-04T15:14:03 prefetch.2.11.2: SRA Normalized Format file is #being retrieved, if this is different from your preference, it may #be due to current file availability. #2022-01-04T15:14:03 prefetch.2.11.2: Downloading via HTTPS... #2022-01-04T15:14:14 prefetch.2.11.2: HTTPS download succeed #2022-01-04T15:14:14 prefetch.2.11.2: 'SRR17327077' is valid #2022-01-04T15:14:14 prefetch.2.11.2: 2) 'SRR17327077' was downloaded successfully #2022-01-04T15:14:14 prefetch.2.11.2: 'SRR17327077' has 0 unresolved dependencies #2022-01-04T15:14:15 prefetch.2.11.2: Current preference is set to #retrieve SRA Normalized Format files with full base quality scores. #2022-01-04T15:14:16 prefetch.2.11.2: 3) Downloading 'SRR17327078'... #2022-01-04T15:14:16 prefetch.2.11.2: SRA Normalized Format file is #being retrieved, if this is different from your preference, it may #be due to current file availability. #2022-01-04T15:14:16 prefetch.2.11.2: Downloading via HTTPS... #2022-01-04T15:14:26 prefetch.2.11.2: HTTPS download succeed #2022-01-04T15:14:26 prefetch.2.11.2: 'SRR17327078' is valid #2022-01-04T15:14:26 prefetch.2.11.2: 3) 'SRR17327078' was downloaded successfully #2022-01-04T15:14:26 prefetch.2.11.2: 'SRR17327078' has 0 unresolved dependencies
実行後に、以下のように、3つのフォルダが生成される。 ただ、別々のフォルダに保存されるので、まとめ作業を後でしないといけないかも。

補足
シェルスクリプトで、複数のFASTA形式ファイル(+ gz圧縮)をダウンロードする。
簡単なシェルスクリプトを書いて、for-ループを実行することで、 SRR_Acc_ListR.txtを読み込んで、複数のFASTA形式ファイルを取得することも可能である。
複数のFASTA形式ファイル(1行あたり60塩基)を取得して、 gz圧縮する場合のシェルスクリプトの実行コードを以下に示す。
#複数のFASTA取得(1行あたり60塩基) + gz圧縮 while read line; do; fastq-dump --gzip --fasta 60 $line; done < ./SRR_Acc_ListR.txt #Read 100959 spots for SRR17327076 #Written 100959 spots for SRR17327076 #Read 112855 spots for SRR17327077 #Written 112855 spots for SRR17327077 #Read 101553 spots for SRR17327078 #Written 101553 spots for SRR17327078
実行後に、以下のように、3つの.fasta.gzファイルが生成される。